This is my story of how I attempt to build an AI-powered pipeline for ArXiv papers. It was a journey that started with a cool idea about AI agents and ended with me wrestling Docker, n8n, and Python into submission.
Part 1: The AI Agent Dream (and Subsequent Nightmare)#
My first idea was to build a smart AI agent using n8n that could talk to ArXiv. I wanted an LLM that could actually search for papers, download them, and even read them.
The Docker Model Context Protocol (MCP) looked like the perfect tool for this. I found an arxiv-mcp-server on GitHub and my first task was just getting the thing to build.
Building the ArXiv Server#
I found the repo above, which had already configured an mcp server just as I wanted. However, when I attempted to get it running, I found the original Dockerfile was… a bit much. I figured I could simplify it using uv, since its official base images are clean and come with it pre-installed.
My new Dockerfile was way simpler:
# Use a single Python base image with 'uv' pre-installed
FROM ghcr.io/astral-sh/uv:python3.11-bookworm-slim
WORKDIR /app
COPY . .
# Install the project and all its deps
RUN uv pip install . --system
# Run the server
ENTRYPOINT ["python", "-m", "arxiv_mcp_server"]
The “Stateless” Problem#
With the server built, I set up a custom catalog.yaml above to define my tools and hooked it all into docker-compose.yml. A custom catalog is essentially your own personal, self-contained list of MCP servers. Instead of relying on a public registry, you define everything about the servers you want to use in a single catalog.yaml file.
The process is straightforward:
- Create
catalog.yaml: You define one or more servers in a YAML file following the specified format. - Mount the Catalog: In your
docker-compose.ymlfile, you use a volume mount to make your localcatalog.yamlfile available inside the gateway container.volumes: - ./catalog.yaml:/mcp/catalog.yaml
- Tell the Gateway to Use It: You use
commandarguments to point the gateway to your mounted catalog file and specify which server(s) from that file you want to activate.command: - --catalog=/mcp/catalog.yaml - --servers=duckduckgo
registry:
arxiv-mcp-server:
title: "ArXiv MCP Server"
description: "An MCP server that enables AI assistants to search, download, and read papers from the arXiv research repository."
type: "server"
image: "arxiv-mcp-server:latest"
tools:
- name: "search_papers"
- name: "download_paper"
- name: "list_papers"
- name: "read_paper"
- name: "deep-paper-analysis"
env:
- name: "ARXIV_STORAGE_PATH"
value: "/data"
volumes:
- "/mnt/storage/media/docs:/data"
docker-compose file
services:
n8n:
image: docker.n8n.io/n8nio/n8n
hostname: n8n
ports:
- "5678:5678"
environment:
- N8N_ENFORCE_SETTINGS_FILE_PERMISSIONS=true
- N8N_HOST=${SUBDOMAIN}.${DOMAIN_NAME}
- N8N_PORT=5678
- N8N_PROTOCOL=http
- N8N_RUNNERS_ENABLED=true
- WEBHOOK_URL=https://${SUBDOMAIN}.${DOMAIN_NAME}/
- OLLAMA_HOST=${OLLAMA_HOST:-ollama:11434}
- TZ=${GENERIC_TIMEZONE}
volumes:
- ${APPDATA}/n8n/storage:/home/node/.n8n
- ${SHARED_FOLDER}:/files
restart: always
mcp-gateway:
image: docker/mcp-gateway
hostname: mcp-gateway
ports:
- "8811:8811"
command:
- --servers=arxiv-mcp-server
- --catalog=/mcp/catalog.yaml
- --transport=sse
- --port=8811
volumes:
- /var/run/docker.sock:/var/run/docker.sock
- ./catalog.yaml:/mcp/catalog.yaml
I then wired it up in n8n with an AI Agent node, first trying a local qwen3 model (way too slow) and then switching to gpt-4o-mini (much faster).

It worked! The agent called the search_papers tool.
Then, I hit the first major wall. The agent would download_paper, and on the very next step, the read_paper tool would fail.
The Problem: The MCP gateway, by default, is stateless. It spins up a brand new container for every single tool call. The container that downloaded the paper was instantly destroyed, so the new container for read_paper had no idea the file existed. Bruh.
The “Static” Mode Saga#
The fix was static=true mode. This tells the gateway to connect to an already-running server container. I dutifully refactored my docker-compose.yml to have mcp-gateway depend on a long-running mcp-arxiv-server.
mcp-gateway:
image: docker/mcp-gateway
hostname: mcp-gateway
ports:
- "8811:8811"
command:
- --servers=arxiv-mcp-server,duckduckgo
- --static=true
- --transport=streaming
- --port=8811
depends_on:
- mcp-arxiv-server
mcp-arxiv-server:
image: mcp/arxiv-mcp-server
entrypoint:
["/docker-mcp/misc/docker-mcp-bridge", "python", "-m", "arxiv_mcp_server"]
init: true
labels:
- docker-mcp=true
- docker-mcp-tool-type=mcp
- docker-mcp-name=arxiv-mcp-server
- docker-mcp-transport=stdio
volumes:
- type: image
source: docker/mcp-gateway
target: /docker-mcp
- ${SHARED_FOLDER}:/app/papers
It failed.
I tried the exact same setup with the official duckduckgo server, and it worked perfectly. My ArXiv server? Nothing. Just network errors.

I was losing my mind, so I filed a GitHub issue. A collaborator saved me. Turns out, the gateway auto-prefixes the server name with mcp- to find the service.
My service was named mcp-arxiv-server. The gateway was looking for mcp-mcp-arxiv-server.
I renamed my service to arxiv-mcp-server (so the gateway would find it at mcp-arxiv-mcp-server) and just like that, it worked. The agent could finally search, download, and read papers in one session.

Part 2: The New Task - Batch Processing 300 PDFs#
Right after that win, I had a meeting with Lokman Belkit. We shifted gears. I now had a folder of 300 PDFs he’d sent me. The priority was no longer the live agent, but batch-processing this existing data.

I needed a good PDF-to-Markdown converter. LlamaParse looked amazing, but you have to negotiate a license. No thanks. I settled on Docling because it was open-source and had a docling-serve image.
Configuring docling-serve#
This took way longer than I expected. docling-serve is great, but it needs to download all its models before it can run. I ended up creating a two-stage setup in my docker-compose.yml:
docling-serve-initial: A service that runs once (restart: "no") and just runs the download command, saving the models to a shared Docker volume.docling-serve: The main server. Itdepends_ontheinitialservice, mounts that same volume, and reads the pre-downloaded models.
services:
# To download the required models before first run
docling-serve-initial:
image: ghcr.io/docling-project/docling-serve-cu126:main
command:
- docling-tools
- models
- download
- --all
volumes:
- ${APPDATA}/n8n/docling_artifacts:/opt/app-root/src/.cache/docling/models
restart: "no"
# For document parsing
docling-serve:
image: ghcr.io/docling-project/docling-serve-cu126:main
hostname: docling-serve
ports:
- "5001:5001"
environment:
DOCLING_SERVE_ENABLE_UI: "true"
NVIDIA_VISIBLE_DEVICES: "all"
DOCLING_SERVE_ARTIFACTS_PATH: "/models"
DOCLING_SERVE_ENABLE_REMOTE_SERVICES: "true"
DOCLING_SERVE_ALLOW_EXTERNAL_PLUGINS: "true"
deploy: # This section is for compatibility with Swarm
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
volumes:
- ${APPDATA}/n8n/docling_artifacts:/models
runtime: nvidia
restart: always
depends_on:
docling-serve-initial:
condition: service_completed_successfully
First, I tried to get n8n to load all the papers from the arxiv-existing folder Lokman sent me. It contained 56 items, and it took a really long time to load. Next, I started poking around the docling API. Before unleashing it on all 56 papers, I tested it out with just two to see what would actually happen.
I first tried all of the features that docling offers:
pipeline(str). The choice of which pipeline to use. Allowed values arestandardandvlm. Defaults tostandard.do_table_structure(bool): If enabled, the table structure will be extracted. Defaults to true.do_code_enrichment(bool): If enabled, perform OCR code enrichment. Defaults to false.do_formula_enrichment(bool): If enabled, perform formula OCR, return LaTeX code. Defaults to false.do_picture_classification(bool): If enabled, classify pictures in documents. Defaults to false.do_picture_description(bool): If enabled, describe pictures in documents. Defaults to false.
However, it took a ridiculous amount of time and memory to run, and it was prone to crashing. After digging around, I found out that other people were hitting this same issue. The formula and code awareness models, while small, will apparently eat your entire GPU VRAM. So I had to turn off all the enrichments.
Part 3: The n8n Orchestration Nightmare#
This was my first time really using n8n for a complex batch job, and honestly, it was frustrating.
Problem 1: The ZIP File
docling-serve returns a ZIP file with paper.md and an artifacts/ folder. n8n’s “Decompress” node doesn’t output a nice array you can loop over. It’s… not an array. It’s a single item with multiple binary properties. After digging through forums, I found you have to use a custom Code node to manually split it:
// This code is required to split a single item with multiple binary files
// into multiple items, each with one binary file.
let results = [];
for (item of items) {
for (key of Object.keys(item.binary)) {
results.push({
json: { fileName: item.binary[key].fileName },
binary: { data: item.binary[key] }
});
}
}
return results;
Problem 2: Nested Loops are Buggy My next instinct was one giant workflow:
- Loop over all 50 PDFs.
- (Nested) Call Docling API.
- (Nested) Get the ZIP, run the code above.
- (Nested) Loop over the resulting files to save them.
This failed miserably. Data from the first paper’s loop would “bleed” into the second paper’s execution. It would just process the first paper over and over.
The Solution: Master/Child Workflows The only stable solution was to refactor:

- Master Workflow: Its only job is to loop through the 50 PDFs and call a “Child” workflow once per paper.
- Child Workflow: Receives one paper, calls Docling, saves the files, and finishes.
This isolated the execution and finally worked. I also created a merge node to filter out previously processed items, in case I wanted to run the workflow again in the future.
This process might look easy, but it took me several hours. At first, I didn’t know the Edit Fields node existed, so I was comparing the filenames directly, without realizing the file extensions were different (silly me). I had to modify the items in the output node, using an expression to cut the .md extension and replace it with .pdf just to get the filter to work.
In the end, it processed 39 papers in 11 minutes (with table enrichment on). A success… but it felt way too complicated.

Part 4: The Final Pivot - From n8n Hell to Python#
The next step was extracting metadata from these new Markdown files.
I briefly tried pdfVector because of its JSON schema feature. Then I saw the price: 2 credits per page. A 25-page paper would cost 75 credits. It was a complete non-starter. The results was actually good tho. At least I can utilize the JSON schema of it.

{
"type": "object",
"properties": {
"title": {
"type": "string",
"description": "Title of the research paper"
},
"type": {
"type": "string",
"description": "Type of the paper",
"enum": [
"method",
"benchmark",
"dataset",
"application",
"survey",
"other"
]
},
"categories": {
"type": "array",
"description": "A list of the paper's methodology.",
"items": {
"type": "string",
"enum": [
"Weakly Supervised",
"Semi Supervised",
"Training Free",
"Instruction Tuning",
"Unsupervised",
"Hybrid"
]
}
},
"github_link": {
"type": "string",
"format": "url",
"description": "Link to the GitHub repository (if available)",
"nullable": true
},
"summary": {
"type": "string",
"description": "Description of the novelty of the paper"
},
"benchmarks": {
"type": "array",
"description": "A list of benchmarks used in the paper",
"items": {
"type": "string",
"enum": [
"cuhk-avenue",
"shanghaitech",
"xd-violence",
"ubnormal",
"ucf-crime",
"ucsd-ped",
"other"
]
},
"nullable": true
},
"authors": {
"type": "array",
"description": "A list of the paper's authors",
"items": {
"type": "string"
}
},
"date": {
"type": "string",
"format": "date",
"description": "Publication date of the paper (YYYY-MM-DD)"
}
},
"required": [
"title",
"type",
"categories",
"date",
"summary"
],
"additionalProperties": false
}
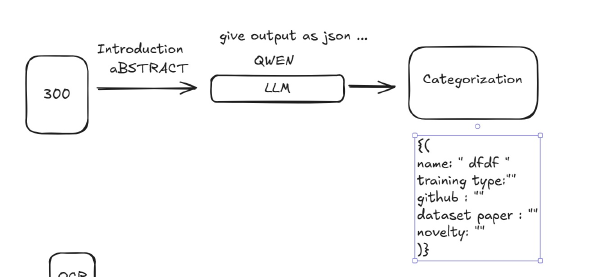
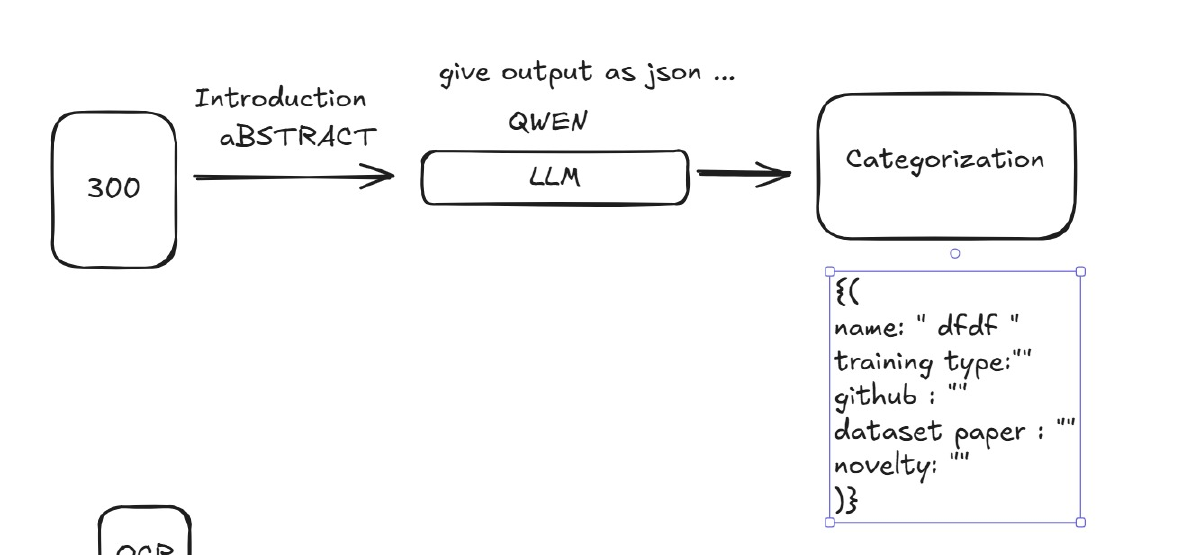
So I decided to roll my own json extractor on n8n. I added an “Information Extractor” node to my n8n workflow, using the JSON schema I’d built. Again, the local model disappointed me with inferior results.
- Local
qwen3-4b: Failed to call the tool.
- OpenRouter
gpt-4.1-nano: Worked perfectly.
The final nail in the n8n-coffin came when I tried to set up my Hugo site. To make images work, Hugo needs a “Page Bundle” structure:
- content/
----papers/
-------<paper-name>/
-----------index.md
-----------artifacts/
---------------image.png
Trying to make n8n create this dynamic directory (<paper-name>) and rename the file to index.md was a joke. I was writing crazy expressions, using Execute Command nodes, Edit Fields nodes… it was just a mess.
I was so frustrated with how n8n handles basic file and path manipulation that I just gave up on it for orchestration.
The Final Architecture: Python as the Orchestrator#
I threw away the complex “Master” n8n workflow and replaced it with a single Python script.
This new hybrid architecture is the best of all worlds:
- Python (
main.py) is the “Master.” It’s simple, I can debug it, and it handles file I/O perfectly. - Docker runs my services (
docling-serve,n8n,mcp-server). - n8n is now just a simple “serverless function.” It’s a single webhook that receives a file path, extracts the JSON, and sends it back.
Here’s the new flow:
- Python script loops through all PDFs.
- Calls
docling-serve(running in Docker) to get the ZIP. - Unzips the files locally into the correct Hugo Page Bundle structure (
<paper-name>/index.md). - Calls the n8n webhook with the absolute path to the new
index.md. - The n8n workflow reads the file, extracts the JSON using the LLM, and sends the JSON back as the webhook response.
- Python receives the JSON, formats it with
ruamel.yaml, and writes it as front matter to the top of theindex.md. - The script moves the original PDF to a
donefolder.
This journey was… a lot. But the final system is clean, robust, and a perfect example of using the right tool for the right job—even if it takes a few frustrating detours to find it.