This repository contains the source code for the “SIS ArXiv VAD Papers” website, a Hugo static site using the Blowfish theme.
This project is a comprehensive platform for managing, processing, and displaying ArXiv research papers. It combines a Hugo static site with a powerful backend of containerized services for AI-driven PDF processing, metadata extraction, and ArXiv interaction.

Features#
- ArXiv AI Agent: Includes an
mcp-arxiv-mcp-server, which allows AI assistants to search, download, and read papers directly from the ArXiv repository. - Automated PDF-to-Markdown: Uses the GPU-accelerated
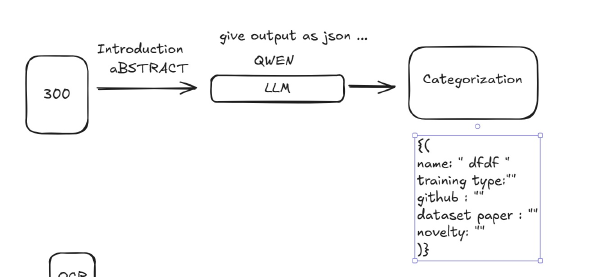
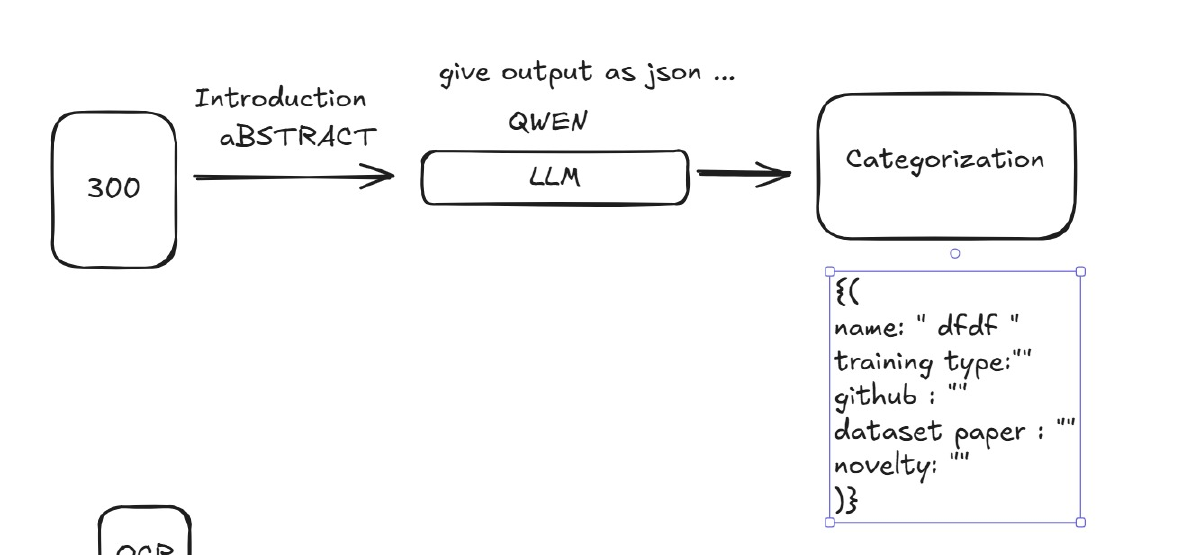
docling-serveto convert complex PDFs into clean Markdown. - AI Metadata Extraction: A Python script orchestrates a pipeline that calls an
n8nworkflow to extract structured JSON metadata (title, authors, date, etc.) from converted text. - YAML Front Matter: Automatically writes the extracted JSON back into the Markdown files as clean YAML front matter, making them ready to publish.
- Hugo Static Site: A clean, modern, and fast website built with Hugo and the Blowfish theme.
Architecture & Services#
The project’s backend is defined in the docker/compose.yml file and includes several key services:
n8n: The workflow automation service. It is used here as an API endpoint (via Webhook) to run the AI metadata extraction pipeline. It is also used to connect themcp-arxiv-mcp-serverto integrate with an LLM model for searching and downloading the latest papers.docling-serve: A powerful, GPU-enabled service that handles the core PDF-to-Markdown conversion. It is pre-loaded with models via thedocling-serve-initialservice.mcp-gateway&mcp-arxiv-mcp-server: A service that provides an AI-readable interface to the ArXiv repository, allowing for programmatic searching, downloading, and reading of papers.- Python Pipeline (
scripts/): This is the “glue” that connects everything. It is a host-run script that:- Finds new PDFs in an input directory.
- Calls
docling-serveto convert the PDF to Markdown. - Renames the output to
index.mdin a newcontent/papers/bundle. - Calls the
n8nwebhook with the path to the newindex.md. - Receives the extracted JSON metadata back from n8n.
- Writes this JSON as YAML front matter into the
index.mdfile.
File Structure#
.
├── archetypes/ # Hugo new content templates
├── assets/ # Site assets (images, etc.)
├── config/ # Hugo configuration
├── content/ # The Markdown content for the site
│ └── papers/ # <-- Processed, AI-enhanced articles land here
├── docker/ # Docker service definitions
│ ├── compose.yml # The main Docker Compose file for all services
│ └── catalog.yaml # Describes the ArXiv MCP service
├── scripts/ # The Python automation pipeline
│ ├── config.py # Holds paths and API configs
│ ├── main.py # Main script to run the pipeline
│ ├── .env # (Not shown) Stores secret keys
│ ├── pyproject.toml # Python project definition
│ └── uv.lock # Python dependencies
├── static/ # Static files (favicons, etc.)
├── themes/ # Hugo themes
│ └── blowfish/
└── hugo.toml # Main Hugo configuration file
Setup & Installation#
Clone the Repository:
git clone https://github.com/phuchoang2603/sis-arxiv-vad-papers.git cd sis-arxiv-vad-papersConfigure Docker Environment: Create a
.envfile in the project’s root directory (next todocker/). This will provide environment variables to yourcompose.yml.# ./.env # -- Docker Services -- # MUST be an absolute path to your shared data folder SHARED_FOLDER=/path/to/your/shared/data # MUST be an absolute path for persistent Docker data APPDATA=/path/to/your/appdata/sis-arxiv # -- n8n -- SUBDOMAIN=n8n DOMAIN_NAME=your-domain.com GENERIC_TIMEZONE=America/New_YorkConfigure n8n Workflow:
- Start your n8n instance and create your metadata extraction workflow.
- Start Node: Use a Webhook node.
- Authentication: Set to
Header Authand create a secure, random API key. - Response Mode: Set to
Respond at End of Workflow. This is critical for getting the JSON response back. - Workflow: Add a
Read Binary File from Disknode (using the path from the webhook), anExtract from Filenode, and yourInformation Extractornode. - Activate: Click the “Active” toggle in the top-right.
- Copy: Copy the Production URL.

Configure Python Pipeline: Create a separate
.envfile inside thescripts/directory for the Python script.# scripts/.env N8N_WEBHOOK_URL="https://n8n.your-domain.com/webhook/..." # <-- Your n8n PRODUCTION URL N8N_API_KEY="your-secret-n8n-header-auth-key"Run Docker Services: Run this command from the project’s root directory:
docker-compose -f docker/compose.yml up --build -dThis will build and start
n8n,docling-serve, and the other services.Install Python Dependencies: Navigate to the
scriptsdirectory and useuvto install:cd scripts uv sync
How to Use the Pipeline#
- Add PDFs: Place your
.pdffiles into the input directory defined inscripts/config.py. (By default, this points to../../arxiv_existing/test, which is a directory sibling to your project folder). - Run Pipeline:
cd scripts python main.py - Check Output: Watch the terminal as the script processes each file. Your new content bundles, complete with
index.mdand YAML front matter, will appear incontent/papers/. - Preview Site:Your site will be available at
cd .. # Return to the Hugo root hugo serverhttp://localhost:1313.
License#
This project is licensed under the MIT License.