

AnyAnomaly: Zero-Shot Customizable Video Anomaly Detection with LVLM#
Sunghyun Ahn * *, Youngwan Jo * *, Kijung Lee, Sein Kwon, Inpyo Hong, Sanghyun Park † Yonsei University, Seoul, Korea
{skd, jyy1551, rlwjd4177, seinkwon97, hip9863, sanghyun}@yonsei.ac.kr
Abstract#
Video anomaly detection (VAD) is crucial for video analysis and surveillance in computer vision. However, existing VAD models rely on learned normal patterns, which makes them difficult to apply to diverse environments. Consequently, users should retrain models or develop separate AI models for new environments, which requires expertise in machine learning, high-performance hardware, and extensive data collection, limiting the practical usability of VAD. To address these challenges, this study proposes customizable video anomaly detection (C-VAD) technique and the AnyAnomaly model. C-VAD considers userdefined text as an abnormal event and detects frames containing a specified event in a video. We effectively implemented AnyAnomaly using a context-aware visual question answering without fine-tuning the large vision language model. To validate the effectiveness of the proposed model, we constructed C-VAD datasets and demonstrated the superiority of AnyAnomaly. Furthermore, our approach showed competitive performance on VAD benchmark datasets, achieving state-of-the-art results on the UBnormal dataset and outperforming other methods in generalization across all datasets. Our code is available online at github.com/SkiddieAhn/Paper-AnyAnomaly .
1. Introduction#
Video anomaly detection (VAD) aims to detect abnormal events in video streams. Abnormal events include the actions of objects that are inappropriate for the environment (e.g., climbing over a fence) or objects with unusual appearances (e.g., a bicycle on a walkway). However, abnormal events are rare and diverse, making it difficult to construct large-scale datasets for VAD. Therefore, the VAD is recognized as a highly challenging problem.
To overcome these limitations, previous studies primarily used one-class classification (OCC) methods that learn only from normal data. In the OCC approach, the model
- Equal contribution
† Corresponding author
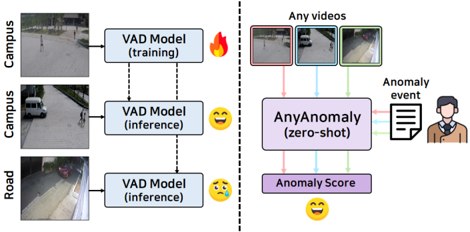
Figure 1. Comparison of traditional video Anomaly Detection (VAD) and customizable video anomaly detection (C-VAD). Traditional VAD models struggle with generalization, making them hard to apply in diverse environments, while C-VAD can handle various video environments.
learns normal patterns and classifies the cases that deviate from them as abnormal. Representative OCC methods include classification-[14 , 30 , 39], distance-[2 , 27 , 29], and prediction-based methods [10 , 15 , 17 , 37], all of which have demonstrated excellent performance in VAD tasks.
However, because normal and abnormal classes can be defined differently depending on the environment, OCC methods cannot always guarantee a generalized performance. For example, as shown on the left side of Figure 1, a model trained in a campus environment learns the characteristics of a ‘person’ as a normal pattern and classifies a ‘car’ as abnormal. However, when this model is applied to a road environment, a ‘car’ is still detected as abnormal, which can increase the number of false positives. Therefore, OCC methods require the retraining of normal patterns for each new environment, which entails additional costs, such as data collection, expert intervention, and high-performance equipment. Because of these limitations, the application of VAD models to real-world scenarios is challenging.
To address this issue, we propose a novel technique called customizable video anomaly detection (C-VAD). CVAD considers user-defined text as abnormal events and detects the frames containing these events in the video. For instance, in campus videos, ‘car’ can be set as an abnormal event, while in road videos, ‘person’ can be set as an abnor-
mal event. In contrast to existing VAD models, which judge abnormalities based on learned normal patterns, C-VAD dynamically detects abnormal patterns based on the text provided. This implies that as the generalizability of visual text analysis improves, anomaly detection becomes more effective in various environments. Consequently, we introduce a zero-shot capable C-VAD approach, as shown on the right side of Figure 1, and propose the AnyAnomaly model, which allows for VAD in various environments without the need for additional training.
An effective method to implement zero-shot C-VAD is to leverage large vision language models (LVLMs). Recently, LVLMs have demonstrated outstanding generalization performance in visual text analysis. By leveraging this capability, C-VAD can be performed effectively across various environments. The most intuitive method involves performing visual question answering (VQA) [4] on each frame to estimate the anomaly score. For instance, one could provide the model with the prompt: “Return a value between 0 (no) and 1 (yes) indicating how well the input image represents the text provided by the user”. This was used as the baseline model. However, through experiments, we observed the following limitations of the baseline model: 1 Due to the large computational cost of LVLMs, the latency is high. 2 Difficulty in analyzing specific objects due to the characteristics of surveillance videos, such as foreground-background imbalance and object congestion. 3 Difficulty in detecting action-related anomalies because of the inability to utilize temporal information.
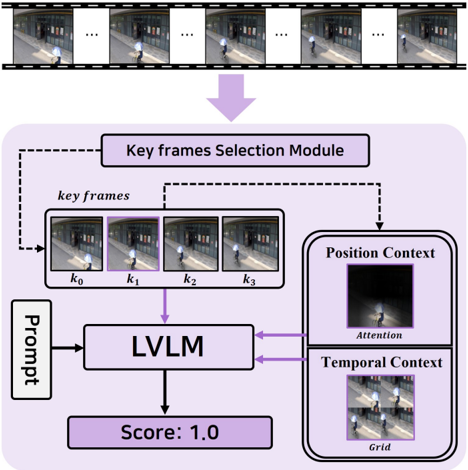
To overcome these limitations, we designed an AnyAnomaly model with the structure shown in Figure 2 . First, to reduce the latency, we adopted a segment-level approach that groups consecutive frames into a single segment for processing. For this purpose, we introduced a key frames selection module (KSM) that selects key frames representing the segment and performed VQA per segment. Second, instead of performing simple image-text matching, we introduced a context-aware VQA approach to enable a deeper understanding of the scene. To this end, we additionally utilized two types of information: position context, P C and temporal context, T C . P C is a context that emphasizes important locations within a frame, enhancing the object analysis capability of the LVLM. T C is a context that structures scene changes over time into a grid format, improving the action analysis capability of the LVLM. Notably, the proposed KSM and context generation modules operate in a training-free manner, allowing for easy application of C-VAD without additional data training.
To evaluate the performance of C-VAD, we classified existing VAD benchmark datasets based on anomaly types to create the C-VAD datasets. Through this process, we demonstrated the superiority of AnyAnomaly. Furthermore, despite being a zero-shot approach, AnyAnomaly achieved
Figure 2. The architecture of AnyAnomaly
competitive performance on VAD datasets compared to traditional OCC-based VAD models. It achieved state-of-theart (SOTA) results on the UBnormal dataset [1] and showed superior generalization across all datasets. The proposed approach is expected to be an effective solution for deploying VAD technology in real-world applications. The contributions of this study are as follows:
- We propose the C-VAD technique for anomaly detection in diverse environments. To the best of our knowledge, it is the first to perform VAD based on user-defined anomalies.
- We develop the AnyAnomaly model, which applies context-aware VQA to perform C-VAD effectively.
- To evaluate the performance of C-VAD, we construct new C-VAD datasets and experimentally verify the superiority of AnyAnomaly.
- AnyAnomaly achieves SOTA performance on UBnormal dataset and outperforms other methods in generalization across all datasets.
2. Related Work#
Video Anomaly Detection. Most VAD models adopt the OCC approach to detect anomalies by learning normal patterns. Among them, prediction-based methods train models to predict future or past frames based on normal frames, assuming that abnormal frames exhibit larger prediction errors. Liu [17] proposed a method that utilizes FlowNet [11] and GANs [23] to predict the t + 1-th frame
given t input frames. Yang [37] introduced an approach that selects key frames from t input frames to predict the entire sequence. However, because the definitions of normal and abnormal patterns may vary depending on the environment, the OCC approach, which relies on learned normal patterns, has a limited generalization performance. To mitigate this limitation, recent studies have explored cross-domain VAD (xVAD). Notably, zxVAD [3] enhances the adaptability to new environments by synthesizing abnormal patterns using the cut mix technique on images from auxiliary datasets. However, these approaches depend on fixed data transformations, making it difficult to fully capture the diverse abnormal patterns that may occur in real-world scenarios. Therefore, we propose a novel VAD method that uses textual information to dynamically detect abnormal patterns that vary depending on the environment.
Large Vision Language Models. Large language models have primarily been used in natural language processing; however, they have recently been applied to multimodal tasks such as image captioning and VQA. For example, MiniGPT-4 [41] processes multimodal inputs by connecting a pre-trained vision encoder to the Vicuna [7] model through a linear layer. Recent LVLMs have employed novel visual encoding techniques to better understand images. Chat-UniVi [13] generates dynamic tokens for images, thereby reducing unnecessary information and effectively extracting key visual features. This model enables flexible analysis by applying dynamic tokens across various resolutions. MiniCPM-V [38] applies the best partition technique according to the image resolution and generates tokens optimized for each segment, thereby improving the memory efficiency. However, despite the advancements in LVLMs, they are trained for general purposes, making their direct application in VAD challenging. To handle VAD effectively, it is essential to consider the characteristics of surveillance videos and leverage temporal information. Therefore, we propose a training-free approach to minimize the domain gap between the LVLMs and VAD tasks.
3. Method#
3.1. Overview#
Figure 2 illustrates the structure of the AnyAnomaly model, which performs context-aware VQA. The input is a video segment S = {s0, . . . , sN − 1 } comprising N frames, where N is a multiple of 4. The KSM selects key frames K = {k0, . . . , k3} from S. Among the selected key frames, the representative frame ˆ k is used to generate PC, whereas K is used to create T C. Subsequently, ˆ k , P C, and T C are utilized as image inputs for the LVLM, whereas the userprovided text X is combined with a prompt and used as the text input. Finally, the LVLM’s response results are integrated to compute an anomaly score.
The user-defined text X refers to a natural language description of the anomaly the user wishes to detect. It can be a single word (e.g., “bicycle”), diverse events (e.g., “jumping-falling”), or a complex behavior (e.g., “driving outside the lane”). In the case of diverse events, each event keyword is processed individually as a single word.
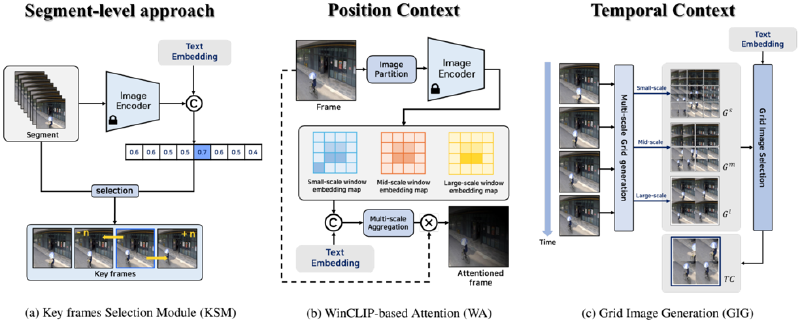
3.2. Key frames Selection Module#
Figure 3a shows KSM, a key component of the segmentlevel approach. For this purpose, we selected four frames representing the segment as K and utilized the CLIP [25] model, which was trained to match the images and text.
Specifically, S and X are inputs to the image encoder E I and text encoder E T , respectively, and the similarity is calculated using the dot product of N image and text embeddings. The frame with the highest similarity is selected as the representative frame ˆ k .
The index of the representative frame ˆ k, denoted as ˆ i, is used to select the other key frames. We divide the segment into four groups of equal size and select the ˆ i mod N 4 -th frame from each group. For example, when N = 8 and ˆ i = 4, the 0-th frame from each group is selected and the final set is K = {s0, s2, s4, s6}. This process is defined as follows:
Using the KSM, K is generated by considering both text alignment and temporal uniformity, thereby enabling effective context generation. A comparative analysis of the key frames selection method is presented in Section 4.5 .
3.3. Context Generation#
P C and T C are key elements of context-aware VQA, serving as additional information that complements the input image. P C enhances the object analysis capability of the LVLM and is generated through WinCLIP-based attention (WA). T C strengthens the action analysis ability of the LVLM and is created through grid image generation (GIG).
WinCLIP-based Attention. Figure 3b illustrates the WA method. We emphasize the regions related to X at ˆ k based on WinCLIP, as proposed by Jeong [12]. First, ˆ k is divided into multiple windows, and individual embeddings are generated from each window using EI . For example, when the image size is 240 × 240, it is divided into 25 windows of size 48 × 48, and the embeddings of each window are
Figure 3. Architecture of the proposed modules. KSM is essential for the segment-level approach, and WA and GIG are crucial for context generation.
collected to create a small-scale window embedding map W s ∈ R 25×D . By adjusting the window size, a middlescale window embedding map W m and large-scale window embedding map W l are also generated, and the similarity between these embedding maps and the text embedding z ∈ R D is calculated. The final similarity map M is generated by averaging the similarities calculated on three scales:
We combined the template proposed by Jeong [12] with X and passed it through ET to generate z. Finally, we multiplied M and ˆ k to create P C:
Here, fn fnorm represents min-max normalization, and ⊙ denotes element-wise multiplication. M was used after interpolation and reshaping to match the resolution of ˆ k . Because P C is created by integrating similarities from multiple scales, it is robust to object size and location, and operates effectively even in situations with multiple objects.
Grid Image Generation. Figure 3c illustrates the GIG method, which comprises two stages. In the multiscale grid generation stage, K is used to create grid images at different scales. Similar to the process described in WA, each frame of K is divided into multiple windows, and the windows at the same position are connected in a 2×2 grid format to create a single grid image. This process is defined as follows:
Here, u i j refers to the i-th window created from k j , and g i refers to the i-th grid image. We defined the sets of grid images generated using small-, middle-, and large-scale windows as G s , G m , and G l , respectively.
In the grid image selection stage, the previously created sets are aggregated to generate G all . Then, using the same method as in KSM to select ˆ k, the grid image with the highest similarity to the text is chosen to generate T C:
The T C generated through this process represents the object movement over time within the same background, making it advantageous for action analysis and robust to various object sizes. An analysis of the window sizes used in the WA and GIG is presented in Section 4.5 .
3.4. Anomaly Detection#
Instead of tuning the LVLM, we propose a new prompt and context for performing context-aware VQA. The VQA results were used as anomaly scores to enable training-free zero-shot anomaly detection.
Prompt Design. Figure 4 illustrates the proposed prompt P. The prompt comprises three main components: ’task’, ‘consideration’, and ‘output’. First, ’task’ defines the operation the LVLM should perform, specifically evaluating whether X is present in the image. Next, ‘consideration’ specifies factors to be taken into account during evaluation, while ‘output’ defines the format for presenting the evaluation results. To leverage the chain-of-thought [33] effect,
Figure 4. Proposed prompt for VQA

we instructed the model to provide brief reasoning along with the anomaly score, rounded to one decimal place. When conducting VQA using T C, an additional element, ‘context’, is inserted between ’task’ and ‘consideration’ in the prompt. This context element conveys the meaning of the rows and columns of T C to the LVLM. We define the modified prompt as P ∗ . A comparative analysis of prompts is presented in supplementary materials.
Anomaly Scoring. The context serves as supplementary information to the image. However, because the LVLM accepts only a single image as input, it is challenging to utilize both the original and additional information simultaneously. To address this issue, we adopt a late fusion approach. Specifically, ˆ k , P C, and T C were used as the image inputs for the LVLM. The LVLM returns an anomaly score for each input, and these three scores are combined to compute the final ascore:
Here, γ is a hyperparameter that adjusts the proportion of context reflected in ascore. A performance comparison experiment based on the hyperparameter tuning is presented in supplementary materials.
Consequently, even if the abnormal frame ˆ k receives a low score, the final anomaly score will be high if the additional information, P C or T C, is assigned a high score. This enabled accurate anomaly detection. Finally, to create frame-level anomaly scores, we duplicated the ascore for the length of each segment and then applied a temporal 1-D Gaussian filter for smoothing, following prior works [27 , 32].
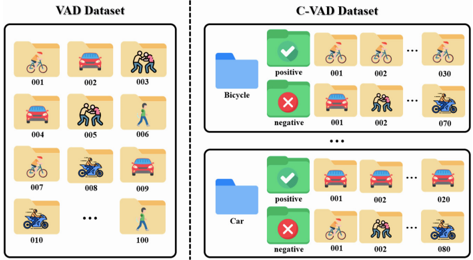
Figure 5. Comparison between the VAD and C-VAD datasets
4. Experiments#
4.1. Datasets#
Figure 5 illustrates the composition of the VAD and proposed C-VAD datasets. In conventional VAD datasets, videos are not categorized by an abnormal class type. In contrast, the proposed C-VAD datasets are organized by abnormal event type, with videos classified as positive or negative based on the presence of each abnormality. This categorization enables a precise evaluation of detection performance for specific types of abnormalities (e.g., bicycle). In this study, we validated the effectiveness of the proposed method on three VAD datasets: CUHK Avenue (Ave) [18], ShanghaiTech Campus (ShT) [20], and UBnormal (UB) [1] as well as two C-VAD datasets: Customizable-ShT (CShT) and Customizable-Ave (C-Ave). Further details of the datasets are provided in supplementary materials.
4.2. Evaluation Criteria#
To ensure consistency with previous VAD studies, the performance of the proposed model was evaluated using the micro-averaged area under the receiver operating characteristic curve (micro AUROC) metric. Specifically, the anomaly scores of all the frames in the dataset were aggregated, and the threshold of the anomaly score was progressively adjusted to compute the final evaluation.
4.3. Results#
Tables 1 and 2 present the evaluation results on the C-VAD datasets. The baseline, as described in Section 1, performs VQA at the frame level to compute anomaly scores. The proposed model achieved performance improvements of 9.88% and 13.65% compared to the baseline on the C-ShT and C-Ave datasets, respectively. Specifically, it showed improvements of 14.34% and 8.2% in the action class, and 3.25% and 21.98% in the appearance class, respectively.
When only KSM was applied to the baseline, the execution time decreased in proportion to the segment length, whereas the average performance remained similar to that
Table 1. Performance comparison on C-ShT dataset
| Category | Class | Baseline | +KSM | +KSM/PC | +KSM/TC | Proposed | Improvement (%) |
|---|---|---|---|---|---|---|---|
| Skateboarding | 61.3 | 57.06 | 57.79 | 73.66 | 73.66 | 20.16 | |
| Throwing | 91.41 | 72.82 | 88.74 | 82.53 | 90.67 | -0.81 | |
| Running | 53.13 | 51.93 | 53.68 | 59.77 | 60.11 | 13.14 | |
| Action | Loitering | 61.98 | 51.96 | 81.27 | 76.94 | 81.27 | 31.12 |
| Jumping | 82.84 | 92.89 | 92.91 | 95.31 | 95.31 | 15.05 | |
| Falling | 78.31 | 78.95 | 79.24 | 88.01 | 88.01 | 12.39 | |
| Fighting | 84.48 | 91.18 | 91.18 | 98.06 | 98.06 | 16.07 | |
| Average | 73.35 | 72 | 77.83 | 82.04 | 83.87 | 14.34 | |
| Appearance | Car | 88.72 | 90.96 | 91.46 | 90.96 | 91.46 | 3.09 |
| Appearance | Hand truck | 95.5 | 98.2 | 98.91 | 99.2 | 99.2 | 3.87 |
| Appearance | Bicycle | 72.36 | 72.46 | 78.47 | 72.46 | 78.47 | 8.44 |
| Appearance | Motorcycle | 88.04 | 86.72 | 86.72 | 86.72 | 86.72 | -1.5 |
| Appearance | Average | 86.16 | 87.09 | 88.89 | 87.34 | 88.95 | 3.25 |
| Overall Average | Overall Average | 78.01 | 77.48 | 81.85 | 83.97 | 85.72 | 9.88 |
Table 2. Performance comparison on C-Ave dataset
| Category | Class | Baseline | +KSM | +KSM/PC | +KSM/TC | Proposed | Improvement (%) |
|---|---|---|---|---|---|---|---|
| Action | Throwing | 78.44 | 80.13 | 89.77 | 82.4 | 89.77 | 14.44 |
| Action | Running | 75.82 | 77.67 | 77.67 | 77.9 | 77.9 | 2.74 |
| Action | Dancing | 85.65 | 72.28 | 76.64 | 91.92 | 91.92 | 7.32 |
| Action | Average | 79.97 | 76.69 | 81.36 | 84.07 | 86.53 | 8.2 |
| Appearance | Too close | 57.23 | 61.48 | 61.48 | 91.78 | 91.78 | 60.37 |
| Appearance | Bicycle | 99.99 | 99.84 | 99.99 | 99.93 | 100 | 0.01 |
| Appearance | Average | 78.61 | 80.66 | 80.74 | 95.86 | 95.89 | 21.98 |
| Overall Average | Overall Average | 79.43 | 78.28 | 81.11 | 88.79 | 90.27 | 13.65 |
of the baseline. This is because the CLIP effectively selects representative frames for each segment, thereby compensating for the loss of temporal information. However, because it does not fully capture fine-grained spatio-temporal details, its performance significantly decreases for certain classes. Therefore, we address these issues using the proposed contextual information. First, using P C resulted in performance improvements of 5.64% and 3.62% compared to the KSM, as the LVLM focused on analyzing objects related to X. Additionally, applying T C led to performance improvements of 8.38% and 14.43% over the KSM, respectively, with particularly notable enhancements observed in the action class. This indicates that utilizing the temporal information provided in the grid image is essential for action analysis. Additional validations, such as FPS comparisons by segment length and performance evaluations across various LVLMs, are presented in supplementary materials.
4.4. Qualitative Analysis#
To analyze the effect of context-aware VQA, we present the visualization results for the anomaly scores and input frames in Figure 6. When P C was not applied, the bicycle object appeared smaller then the other objects, leading to a lower detection performance. Once P C is applied, the bicycle region is emphasized, thereby enhancing the object recognition capability of the LVLM. Similarly, without T C , the model misinterpreted fighting as standing, resulting in lower detection performance. Incorporating temporal information through T C improves the action recognition capability of the LVLM. These results demonstrate that contextaware VQA is more effective than the conventional VQA.
4.5. Ablation Study#
Key frames Selection. We conducted an ablation study on key frames selection from two perspectives: temporal
Figure 6. Anomaly score comparison and context visualization
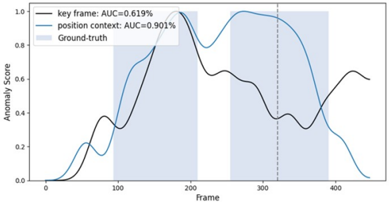
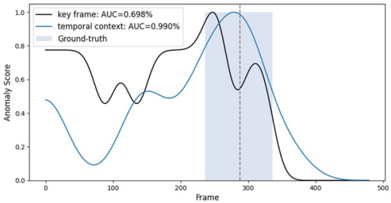




Table 3. Comparison on key frames selection method. RD, CP and Gr. indicate random, CLIP and grouping, respectively. * indicates testing without context. Act. and App. indicate action and appearance class, respectively.
| Key frames | C-ShT | C-ShT | C-ShT | C-Ave ATl | C-Ave ATl | C-Ave
| ATl | ||||||
|---|---|---|---|---|---|---|
| Key | ||||||
| frames | Act. | App. | Total | Act. | App. | Total |
| RD* | 69.9 | 84.0 | 75.0 | 66.4 | 78.8 | 71.3 |
| CP* | 72.0 | 87.1 | 77.5 | 76.7 | 80.7 | 78.3 |
| RD | 80.0 | 89.1 | 83.3 | 79.1 | 92.3 | 84.4 |
| CP | 81.2 | 88.9 | 84.0 | 84.3 | 81.2 | 83.1 |
| Gr. → CP | 82.2 | 88.8 | 84.7 | 83.9 | 92.2 | 87.2 |
| CP → Gr. | 83.9 | 89.0 | 85.7 | 86.5 | 95.9 | 90.3 |
uniformity and text alignment. The random method considers neither of these aspects, whereas the CLIP-based approach considers only text alignment. Selecting key frames using CLIP after grouping ensures text alignment but does not guarantee temporal uniformity. Applying grouping after CLIP resulted in evenly distributed key frames, thereby considering both temporal uniformity and text alignment. As shown in Table 3, incorporating both factors yielded the best performance for C-VAD, highlighting the critical role of temporal uniformity in action recognition. Furthermore, RD* and CP*, which do not utilize the contextual information, perform worse than the random method, which disregards both temporal uniformity and text alignment. This demonstrates the importance of leveraging the contextual information.
Window Size. Table 4 presents the experimental results based on the window sizes used in P C and T C. For the action classes, the best performance was achieved with the large window size in C-ShT and the middle window size in C-Ave. This indicates that middle or large window sizes are more effective in capturing temporal movements and interactions between multiple objects. For appearance classes, the optimal performance was observed with the small window size in C-ShT and the middle window size in C-Ave, suggesting that the appropriate window size varies depending on the dataset owing to differences in object sizes. To enhance the generalization performance of the model, we adopted an approach that utilized all three window sizes and found that incorporating them yielded the best overall performance.
4.6. Comparison with SOTA#
To assess the effectiveness of AnyAnomaly in handling multiple text inputs, we conducted experiments on the VAD benchmark datasets. For performance evaluation, each anomaly class in the dataset was treated as X, and the maximum anomaly score among all computed scores was assigned to the corresponding segment. Table 5 presents a performance comparison with frame-centric VAD methods.
Table 4. Comparison on window size.
| Window Size | C-ShT | C-ShT | C-ShT | C-Ave ATtl | C-Ave ATtl | C-Ave
| ATtl | ||||||
|---|---|---|---|---|---|---|
| Window | ||||||
| Size | Act. | App. | Total | Act. | App. | Total |
| small | 78.8 | 90.6 | 83.1 | 84.7 | 87.1 | 85.7 |
| middle | 81.2 | 89.0 | 84.1 | 87.5 | 92.0 | 89.3 |
| large | 82.1 | 89.7 | 84.9 | 86.8 | 86.4 | 86.6 |
| all | 83.9 | 89.0 | 85.7 | 86.5 | 95.9 | 90.3 |
Table 5. Comparison with state-of-the-art VAD methods. * indicates testing without context.
| Method | Venue | Zero-shot | Ave | ShT | UB |
|---|---|---|---|---|---|
| AMMC-Net[6] | AAAI 21 | ✗ | 86.6 | 73.7 | - |
| STEAL-Net[5] | ICCV 21 | ✗ | 87.1 | 73.7 | - |
| MPN[21] | CVPR 21 | ✗ | 89.5 | 73.8 | - |
| DLAN-AC[36] | ECCV 22 | ✗ | 89.9 | 74.7 | - |
| UBnormal[1] | CVPR 22 | ✗ | - | - | 68.5 |
| FPDM[34] | ICCV 23 | ✗ | 90.1 | 78.6 | 62.7 |
| SLM[31] | ICCV 23 | ✗ | 90.9 | 78.8 | - |
| USTN-DSC[37] | CVPR 23 | ✗ | 89.9 | 73.8 | - |
| AnomalyRuler[35] | ECCV 24 | ✗ | 89.7 | 85.2 | 71.9 |
| MULDE[24] | CVPR 24 | ✗ | - | 81.3 | 72.8 |
| AED-MAE[28] | CVPR 24 | ✗ | 91.3 | 79.1 | 58.5 |
| MA-PDM[40] | AAAI 25 | ✗ | 91.3 | 79.2 | 63.4 |
| AccI-VAD[27] | TMLR 25 | ✗ | - | - | 66.8 |
| AnyAnomaly* | - | ✓ | 81.4 | 77.2 | 73.1 |
| AnyAnomaly | - | ✓ | 87.3 | 79.7 | 74.5 |
Table 6. Generalization performance comparison. Tr.: crossdomain training where models trained on one VAD dataset are evaluated on another. Few.: methods that adapt to the target domain using only a few training samples, Aux.: methods that utilize auxiliary datasets, *: since competitors did not perform crossdomain evaluations on ShT, we present their same-domain results instead.
| Method | Tr. | Few. | Aux. | Ave | ShT |
|---|---|---|---|---|---|
| STEAL-Net[5] | ✓ | ✗ | ✗ | 54.3 | 51.7 |
| Jigsaw[32] | ✓ | ✗ | ✗ | 62.9 | 59.3 |
| rGAN[19] | ✓ | ✓ | ✗ | 76.6 | 77.9* |
| MPN[21] | ✓ | ✓ | ✗ | 78.9 | 73.8* |
| zxVAD[3] | ✓ | ✗ | ✓ | 82.2 | 71.6* |
| Shibao et al.[8] | ✓ | ✗ | ✓ | 86.2 | 78.7 |
| ZS CLIP[25] | ✗ | ✗ | ✗ | 62.3 | 60.9 |
| ZS ImageBind[9] | ✗ | ✗ | ✗ | 64.5 | 61.3 |
| LLaVA-1.5[16] | ✗ | ✗ | ✗ | 67.4 | 59.6 |
| Video-ChatGPT[22] | ✗ | ✗ | ✗ | 76.9 | 69.1 |
| AnyAnomaly | ✗ | ✗ | ✗ | 87.3 | 79.7 |
Despite not being trained on VAD datasets, AnyAnomaly demonstrated a performance comparable to that of SOTA methods. Notably, it achieved a new SOTA performance of 74.5% on the UB dataset, which contains 29 diverse backgrounds and 22 abnormal event types, demonstrating the effectiveness of the proposed model in various environments. Furthermore, while LLM-based methods (e.g., AnomalyRuler) require rule generation and aggregation using a few normal samples, the proposed method achieves competitive performance solely through zero-shot inference, highlighting its practical applicability.
4.7. Generalization Performance Comparison#
Table 6 presents a comparison of the generalization performance of AnyAnomaly. Although STEAL-Net [5] and Jigsaw [32] achieved high accuracy in same-domain testing, their performance was significantly degraded in crossdomain settings. Specifically, on the Ave dataset, the performances of STEAL-Net and Jigsaw decreased as 87.1% → 54.3% and 92.2% → 62.9%, respectively. Similarly, on the ShT dataset, their performance decreased as 73.7% → 51.7% and 84.3% → 59.3%, respectively. This suggests that the existing OCC-based VAD models tend to overfit the training data, making them less effective when applied to new environments. For instance, ‘Too close’ where an object is in close proximity to the camera is considered anomalous in the Ave dataset but normal in the ShT dataset. Consequently, OCC-based models trained on ShT struggle to detect such anomalies.
The zero- and few-shot VAD models designed for xVAD exhibited better generalization performance than the OCCbased models. However, few-shot models depend heavily on the number of K-shot samples, whereas zero-shot models require auxiliary datasets. Training-free methods using VLMs, such as ZS-CLIP and Video-ChatGPT, leverage strong image and video understanding capabilities, outperforming some VAD models. Nevertheless, their performance is still limited by domain gaps. In contrast, AnyAnomaly effectively overcomes these gaps by incorporating contextual information, achieving superior performance.
5. Conclusion#
We propose AnyAnomaly, a novel approach that leverages the LVLM for universal VAD. AnyAnomaly effectively performs the C-VAD by incorporating a segmentlevel approach and context-aware VQA. This design reduces latency when processing large videos and minimizes the domain gap between the LVLM and VAD task. Despite being a zero-shot method, AnyAnomaly demonstrates competitive performance on benchmark datasets and holds promise for real-world VAD. Furthermore, because it operates without any training and enables anomaly detection in any video, it significantly improves accessibility in the VAD domain. We anticipate that AnyAnomaly will contribute substantially to VAD research and practical deployment.
References#
- [1] Andra Acsintoae, Andrei Florescu, Mariana-Iuliana Georgescu, Tudor Mare, Paul Sumedrea, Radu Tudor Ionescu, Fahad Shahbaz Khan, and Mubarak Shah. Ubnormal: New benchmark for supervised open-set video anomaly detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages 20143–20153, 2022. 2 , 5 , 8 , 11
- [2] Sunghyun Ahn, Youngwan Jo, Kijung Lee, and Sanghyun Park. Videopatchcore: An effective method to memorize normality for video anomaly detection. In Proceedings of the Asian Conference on Computer Vision, pages 2179–2195, 2024. 1
- [3] Abhishek Aich, Kuan-Chuan Peng, and Amit K RoyChowdhury. Cross-domain video anomaly detection without target domain adaptation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision , pages 2579–2591, 2023. 3 , 8
- [4] Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Margaret Mitchell, Dhruv Batra, C Lawrence Zitnick, and Devi Parikh. Vqa: Visual question answering. In Proceedings of the IEEE international conference on computer vision, pages 2425– 2433, 2015. 2
- [5] Marcella Astrid, Muhammad Zaigham Zaheer, and Seung-Ik Lee. Synthetic temporal anomaly guided end-to-end video anomaly detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 207–214, 2021. 8
- [6] Ruichu Cai, Hao Zhang, Wen Liu, Shenghua Gao, and Zhifeng Hao. Appearance-motion memory consistency network for video anomaly detection. In Proceedings of the AAAI conference on artificial intelligence, pages 938–946, 2021. 8
- [7] Wei-Lin Chiang, Zhuohan Li, Zi Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E Gonzalez, et al. Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality. See https://vicuna. lmsys. org (accessed 14 April 2023), 2(3):6, 2023. 3
- [8] Shibo Gao, Peipei Yang, and Linlin Huang. Scene-adaptive svad based on multi-modal action-based feature extraction. In Proceedings of the Asian Conference on Computer Vision , pages 2471–2488, 2024. 8
- [9] Rohit Girdhar, Alaaeldin El-Nouby, Zhuang Liu, Mannat Singh, Kalyan Vasudev Alwala, Armand Joulin, and Ishan Misra. Imagebind: One embedding space to bind them all. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 15180–15190, 2023. 8
- [10] Seungkyun Hong, Sunghyun Ahn, Youngwan Jo, and Sanghyun Park. Making anomalies more anomalous: Video anomaly detection using a novel generator and destroyer. IEEE Access, 2024. 1
- [11] Eddy Ilg, Nikolaus Mayer, Tonmoy Saikia, Margret Keuper, Alexey Dosovitskiy, and Thomas Brox. Flownet 2.0: Evolution of optical flow estimation with deep networks. In Pro-
- ceedings of the IEEE conference on computer vision and pattern recognition, pages 2462–2470, 2017. 2
[12] Jongheon Jeong, Yang Zou, Taewan Kim, Dongqing Zhang, Avinash Ravichandran, and Onkar Dabeer. Winclip: Zero/few-shot anomaly classification and segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 19606–19616, 2023. 3 , 4
[13] Peng Jin, Ryuichi Takanobu, Wancai Zhang, Xiaochun Cao, and Li Yuan. Chat-univi: Unified visual representation empowers large language models with image and video understanding. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13700– 13710, 2024. 3 , 11 , 12 , 13
[14] Dongha Lee, Sehun Yu, and Hwanjo Yu. Multi-class data description for out-of-distribution detection. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 1362–1370, 2020. 1
[15] Kijung Lee, Youngwan Jo, Sunghyun Ahn, and Sanghyun Park. Mdvad: Multimodal diffusion for video anomaly detection. In Pacific-Asia Conference on Knowledge Discovery and Data Mining, pages 121–133. Springer, 2025. 1
[16] Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 26296–26306, 2024. 8
[17] Wen Liu, Weixin Luo, Dongze Lian, and Shenghua Gao. Future frame prediction for anomaly detection–a new baseline. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 6536–6545, 2018. 1 , 2
[18] Cewu Lu, Jianping Shi, and Jiaya Jia. Abnormal event detection at 150 fps in matlab. In Proceedings of the IEEE international conference on computer vision, pages 2720–2727, 2013. 5 , 11
[19] Yiwei Lu, Frank Yu, Mahesh Kumar Krishna Reddy, and Yang Wang. Few-shot scene-adaptive anomaly detection. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part V 16 , pages 125–141. Springer, 2020. 8
[20] Weixin Luo, Wen Liu, and Shenghua Gao. A revisit of sparse coding based anomaly detection in stacked rnn framework. In Proceedings of the IEEE international conference on computer vision, pages 341–349, 2017. 5 , 11
[21] Hui Lv, Chen Chen, Zhen Cui, Chunyan Xu, Yong Li, and Jian Yang. Learning normal dynamics in videos with meta prototype network. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15425–15434, 2021. 8
[22] Muhammad Maaz, Hanoona Rasheed, Salman Khan, and Fahad Khan. Video-chatgpt: Towards detailed video understanding via large vision and language models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12585–12602, 2024. 8
[23] Xudong Mao, Qing Li, Haoran Xie, Raymond YK Lau, Zhen Wang, and Stephen Paul Smolley. Least squares generative adversarial networks. In Proceedings of the IEEE international conference on computer vision, pages 2794–2802, 2017. 2
[24] Jakub Micorek, Horst Possegger, Dominik Narnhofer, Horst Bischof, and Mateusz Kozinski. Mulde: Multiscale logdensity estimation via denoising score matching for video anomaly detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18868–18877, 2024. 8
[25] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748–8763. PMLR, 2021. 3 , 8
[26] Hanoona Rasheed, Muhammad Maaz, Salman Khan, and Fahad S. Khan. Llava++: Extending visual capabilities with llama-3 and phi-3, 2024. 12 , 13
[27] Tal Reiss and Yedid Hoshen. An attribute-based method for video anomaly detection. Transactions on Machine Learning Research . 1 , 5 , 8
[28] Nicolae-C Ristea, Florinel-Alin Croitoru, Radu Tudor Ionescu, Marius Popescu, Fahad Shahbaz Khan, Mubarak Shah, et al. Self-distilled masked auto-encoders are efficient video anomaly detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages 15984–15995, 2024. 8
[29] Karsten Roth, Latha Pemula, Joaquin Zepeda, Bernhard Scholkopf, Thomas Brox, and Peter Gehler. Towards to- ¨ ¨ tal recall in industrial anomaly detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14318–14328, 2022. 1
[30] Lukas Ruff, Robert Vandermeulen, Nico Goernitz, Lucas Deecke, Shoaib Ahmed Siddiqui, Alexander Binder, Emmanuel Muller, and Marius Kloft. Deep one-class classifica- ¨ ¨ tion. In International conference on machine learning, pages 4393–4402. PMLR, 2018. 1
[31] Chenrui Shi, Che Sun, Yuwei Wu, and Yunde Jia. Video anomaly detection via sequentially learning multiple pretext tasks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 10330–10340, 2023. 8
[32] Guodong Wang, Yunhong Wang, Jie Qin, Dongming Zhang, Xiuguo Bao, and Di Huang. Video anomaly detection by solving decoupled spatio-temporal jigsaw puzzles. In European Conference on Computer Vision, pages 494–511. Springer, 2022. 5 , 8
[33] Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022. 4 , 11
[34] Cheng Yan, Shiyu Zhang, Yang Liu, Guansong Pang, and Wenjun Wang. Feature prediction diffusion model for video anomaly detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 5527–5537, 2023. 8
[35] Yuchen Yang, Kwonjoon Lee, Behzad Dariush, Yinzhi Cao, and Shao-Yuan Lo. Follow the rules: Reasoning for video anomaly detection with large language models. ArXiv , abs/2407.10299, 2024. 8
[36] Zhiwei Yang, Peng Wu, Jing Liu, and Xiaotao Liu. Dynamic local aggregation network with adaptive clusterer for anomaly detection. In European Conference on Computer Vision, pages 404–421. Springer, 2022. 8
[37] Zhiwei Yang, Jing Liu, Zhaoyang Wu, Peng Wu, and Xiaotao Liu. Video event restoration based on keyframes for video anomaly detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14592–14601, 2023. 1 , 3 , 8
[38] Yuan Yao, Tianyu Yu, Ao Zhang, Chongyi Wang, Junbo Cui, Hongji Zhu, Tianchi Cai, Haoyu Li, Weilin Zhao, Zhihui He, et al. Minicpm-v: A gpt-4v level mllm on your phone. arXiv preprint arXiv:2408.01800, 2024. 3 , 11 , 12 , 13
[39] Jihun Yi and Sungroh Yoon. Patch svdd: Patch-level svdd for anomaly detection and segmentation. In Proceedings of the Asian conference on computer vision, 2020. 1
[40] Hang Zhou, Jiale Cai, Yuteng Ye, Yonghui Feng, Chenxing Gao, Junqing Yu, Zikai Song, and Wei Yang. Video anomaly detection with motion and appearance guided patch diffusion model. arXiv preprint arXiv:2412.09026, 2024. 8
[41] Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mohamed Elhoseiny. Minigpt-4: Enhancing vision-language understanding with advanced large language models. arXiv preprint arXiv:2304.10592, 2023. 3 , 12 , 13
AnyAnomaly: Zero-Shot Customizable Video Anomaly Detection with LVLM#
Supplementary Material#
Table S1. Comparison on prompt tuning
| Prompt Tuning | C-ShT | C-Ave |
|---|---|---|
| Baseline (simple) | 70.38 | 67.58 |
| Baseline (+reasoning) | 71.58 | 72.79 |
| Baseline (+reasoning, consideration) | 78.01 | 79.43 |
| Proposed (simple) | 79.29 | 74.01 |
| Proposed (+reasoning) | 79.79 | 82.09 |
| Proposed (+reasoning, consideration) | 85.72 | 90.27 |
Table S2. Comparison on segment length
| Segment length | C-ShT | C-Ave | FPS |
|---|---|---|---|
| Baseline | 78.01 | 79.43 | 0.96 |
| 8 | 83.83 | 83.96 | 2.67 |
| 16 | 83.45 | 87.45 | 4.49 |
| 24 | 85.72 | 90.27 | 6.67 |
| 32 | 82.5 | 85.94 | 8.45 |
chain-of-thought [33] effect by requiring a simple reason along with the anomaly score. This helps to break down the problem step-by-step, guiding the model to resolve complex issues more systematically. For example, the question “Does the image include jumping? can be divided into two steps: 1. “Is there an object related to jumping (e.g., a person)?” and 2. “Is the object performing a jumping action?” This allows object-level image analysis, leading to more refined predictions. The consideration prompt encourages the assignment of a high score even when X is not central within the image. This prompt was introduced to address the issue where low scores are assigned simply because X exists but is not the central element. The effectiveness of this prompt tuning is compared and analyzed in Table S1 .
The simple prompt instructs the LVLM to output only the anomaly score, while adding reasoning prompt the model to perform reasoning during the score calculation process, and applying consideration prompt encourages the model to focus on the given text. Experimental results showed that using both reasoning and consideration prompt achieved the best performance, suggesting that when the LVLM includes reasoning in the process, it produces more accurate results and can respond more precisely to user instructions through consideration prompt.
A. Experiment Details#
A.1. Dataset Details#
VAD Dataset. We used the CUHK Avenue (Ave) [18], ShanghaiTech Campus (ShT) [20], and UBnormal (UB) [1] datasets. Ave comprises of videos captured by a single camera on a university campus, containing five types of abnormal events; throwing paper, running, dancing, approaching the camera (Too close) and bicycle. ShT is a campus CCTV dataset that includes 13 different background scenes and 11 types of abnormal events; such as bicycles, cars, fighting, and jumping. UB is a synthetic dataset generated using the Cinema4D software, encompassing 29 diverse background scenes, including indoor environments, sidewalks, and etc. It provides a total of 22 abnormal events, including not only challenging-to-detect events such as smoking and stealing but also complex scenarios such as driving outside the lane and people-car accidents.
C-VAD Dataset. We constructed the Customizable-ShT (C-ShT) and Customizable-Ave (C-Ave) datasets. C-ShT reorganizes the test data of ShT into 11 abnormal event types and assigns new labels to each type. For example, in the bicycle category, videos containing bicycles were assigned to positive, whereas all other videos were assigned to negative. The frame-level labels were set to 1 only for frames in which a bicycle appeared in the positive videos. C-Ave was constructed by reorganizing the test data of Ave into 5 abnormal event types, following the same labeling methodology as C-ShT.
A.2. Implementation Details#
In a key experiment using the C-VAD datasets, we employed an efficient Chat-UniVi [13] 7B model, considering the balance between performance and speed. For the VAD dataset experiment, we utilized the effective MiniCPM-V [38] 8B model to achieve optimal performance and compared it with state-of-the-art (SOTA) models. The CLIP model used for key frames selection and context generation was ViT-B/32. For context generation, we adopted large, middle, and small window sizes of (120,120), (80,80), and (48,48), respectively. For C-Ave and Ave, the large window size was set to (240,240). All the experiments were conducted on a single NVIDIA GeForce RTX 3090 GPU.
A.3. Prompt Details#
Figure S1 shows the detailed prompts used in the experiments. First, a reasoning prompt is designed to obtain the
Figure S1. Prompt details. The content written in the simple version is not utilized when applying reasoning.
Table S3. Comparison of different methods on various datasets
| Dataset | Method | Value | AUC |
|---|---|---|---|
| w/o context | |||
| w/o tuning | w/o context | ||
| w/o tuning | 81.4 | ||
| 84.4 | |||
| 873 | 81.4 | ||
| w/o tuning | 1.0, 1.0, 1.0 | 81.4 | |
| 84.4 | |||
| 873 | 81.4 | ||
| w/ tuning | 0.6, 0.3, 0.1 | 81.4 | |
| 84.4 | |||
| 873 | 81.4 | ||
| w/o context | |||
| w/o tuning | |||
| w/ tuning | - | 77.2 | 77.2 |
| w/o tuning | 1.0, 1.0, 1.0 | 77.2 | 77.2 |
| w/ tuning | |||
| / | 0.5, 0.3, 0.2 | 79.7 | 77.2 |
| w/o context | - | 73.1 | 73.1 |
| 0 73.8 | |||
| w/o tuning | 1.0, 1.0, 1.0 | 73.1 | 73.1 |
| 0 73.8 | |||
| w/ tuning | 74.5 | 73.1 | 73.1 |
| 0 73.8 |
B. Additional Quantitative Evaluation#
B.1. Segment length and FPS#
Table S2 presents the performance comparison and FPS based on different segment lengths. The baseline segment length was set to 1. It was observed that deriving anomaly scores at the segment level yields superior performance compared to the baseline, which relies on a single frame. The highest AUC performance was achieved when the segment length is set to 24, reaching 85.72% and 90.27% for C-ShT and C-Ave, respectively. However, excessively long segment length introduces irrelevant information into the temporal context, leading to a decrease in accuracy. Fur- thermore, performing VAD at the segment level resulted in a 594% improvement in the FPS compared with the baseline.
B.2. Hyperparameter Tuning#
We tuned the three hyperparameters γ1, γ2, andγ3 used for the final anomaly score calculation for each VAD dataset. Each hyperparameter controls the influence of the anomaly score derived from the frame, position, and temporal contexts. As shown in Table S3, the optimal hyperparameter values vary across datasets owing to differences in object sizes and abnormal events. Additionally, comparing w/o context, which does not utilize context information, and w/o tuning, where all hyperparameters were set to the same value, we observed performance improvements of 3.0%, 2.2%, and 0.7%, even without hyperparameter tuning. In contrast, the performance differences owing to hyperparameter tuning were 2.9%, 0.3%, and 0.7%, respectively. This demonstrates the effectiveness of our proposed approach in utilizing context information in VAD and proves that it achieves a strong generalization performance even without hyperparameter tuning.
B.3. Diverse LVLM Comparison#
Table S4 presents the results for C-ShT and C-Ave when using various LVLMs. We evaluated the performances of four SOTA LVLMs: Chat-UniVi [13], MiniGPT-4 [41], MiniCPM-V [38], and LLAVA++ [26]. All experiments
Table S4. Comparison of diverse LVLMs. The model highlighted in blue represents the most efficient model for the C-VAD task, while the one highlighted in purple indicates the most effective model.
| LVLM | Pre-trained | C-ShT | C-ShT | C-Ave | C-Ave | FPS |
|---|---|---|---|---|---|---|
| LVLM | Pre-trained | w/o context | Proposed | w/o context | Proposed | |
| Chat-UniVi[13] | Chat-UniVi-7B | 77.5 | 85.7 | 78.3 | 90.3 | 6.67 |
| MiniGPT-4[41] | LLaMA-2 Chat 7B | 54.0 | 67.4 | 53.9 | 55.3 | 1.26 |
| MiniCPM-V[38] | MiniCPM-Llama3-V-2 5 (8B) | 87.7 | 90.1 | 86.3 | 91.0 | 1.36 |
| LLAVA++[26] | LLaVA-Meta-Llama-3-8B-Instruct-FT | 73.3 | 82.8 | 59.0 | 69.4 | 7.25 |
Figure S2. Example of complementarity between position and temporal context. The first example highlights the importance of position context and the second example emphasizes the importance of temporal context.

were conducted using the default settings, and ‘Pre-trained’ refers to the names of the pre-trained model weights. The experimental results demonstrate that incorporating the proposed context-aware VQA improves the performance of all LVLMs. Specifically, the use context-aware VQA leads to improvements ranging from 2.6% to 24.8%. Notably, even MiniCPM, which achieved the best performance without context-aware VQA, and showed additional improvements of 2.7% and 5.4% for C-ShT and C-Ave, respectively, when context-aware VQA was applied. This confirms that leveraging the proposed context-aware VQA is effective for C-VAD. Additionally, we observed that ChatUniVi, with an FPS of 6.67, was the most efficient model, whereas MiniCPM-V achieved the highest performance on both datasets, scoring 90.1% and 91.0%, respectively. Therefore, as mentioned in Appendix A.1, Chat-UniVi was used for the C-VAD experiments and MiniCPM-V was used for the VAD dataset experiments.
C. Additional Qualitative Evaluation#
C.1. Context Complementarity#
In this section, we explain the complementarity between P C and T C in context-aware VQA. Figure S2 visualizes the key frame of a specific segment along with the images generated using WA and GIG for of P C and T C. We also present the results of a context-aware VQA that utilizes these contexts.
In the first row, when the text input was ‘bicycle’, P C successfully identified the bicycle via WA, yielding a score of 1.0. However, the temporal context suffers from a cropping effect due to motion over time, resulting in a lower score of 0.5. In the second row, when the text input is ‘jumping,’ the attention result from WA fails to accurately locate the ‘jumping’ person. Additionally, because of the lack of temporal information, P C was unable to recognize the jumping action, resulting in a score of 0.0. In contrast, T C captured the entire jumping action over time, achieving a score of 0.9.
These results demonstrate that the proposed P C, which focuses on the object appearance, and T C, which leverages temporal information, are complementary. By integrating
Figure S3. Anomaly detection in diverse scenarios. Various abnormal events can emerge over time.
both approaches, we enable an effective generalization of the VAD.
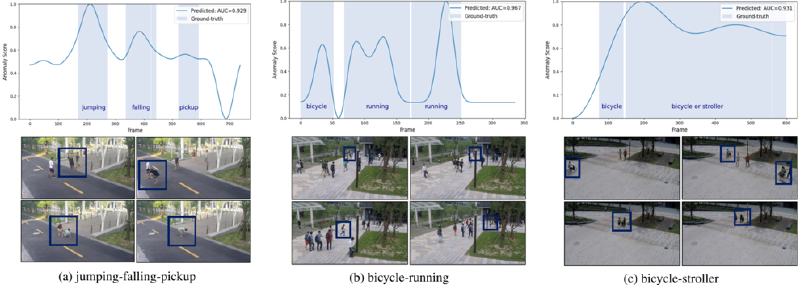
C.2. Anomaly Detection in Diverse scenarios#
Figure S3 visualizes the results of VAD performed on videos containing multiple abnormal classes. The captions in each figure indicate the abnormal classes used in the corresponding video. We input the user-defined abnormal keywords as text individually to obtain the scores, and assigned the highest score as the anomaly score for the corresponding segment. As shown in the visualization results, the proposed AnyAnomaly enables VAD across various types of abnormal events. This demonstrates that AnyAnomaly can be effectively utilized even when the user aims to simultaneously detect multiple abnormal types.
C.3. Anomaly Detection in Complex scenarios#
Figure S4 presents the visualization results of AnyAnomaly on complex scenarios. ‘Key Frame’, ‘Position Context’, and ‘Temporal Context’ visualize ˆ k , P C, and T C, respectively. The text below each figure represents the LVLM output. These visualization results demonstrate that the proposed context-aware VQA, which utilizes P C and T C, is effective and contributes to improving VAD performance.
Additionally, in Figure S4d, we observe that the model can detect certain frames of “walking drunk” even without utilizing context information. This suggests that the strong visual reasoning capabilities of the LVLM enable VAD in complex scenarios. However, as shown in Figure S4a–S4c , relying solely on individual frames is insufficient for fully leveraging these reasoning abilities. Therefore, the proposed context-aware VQA approach is essential for effective VAD.
D. Discussion#
D.1. Comparison with traditional VAD#
Traditional VAD methods and our zero-shot C-VAD each have distinct strengths and limitations. Traditional VAD detects anomalies as deviations from learned normal patterns, requiring no prior knowledge of specific anomaly types and delivering strong performance within the trained environment. However, it often exhibits poor generalization to unseen environments and typically necessitates retraining. In contrast, C-VAD requires prior knowledge of anomaly types but removes the need for retraining or additional data collection even when the definition of “normal” varies across users or environments. This makes it a practical and cost-effective solution for real-world applications. We anticipate that, with continued advances in LVLM technology, the proposed C-VAD will become even more effective in the future.
D.2. Limitation#
Efficiency is crucial in VAD; therefore, we utilized the most lightweight model among the SOTA LVLMs and adopted a segment-level approach to significantly reduce the latency. However, our method still requires three inputs per segment (key frame, position context, and temporal context) and involves a reasoning process, which makes real-time analysis more challenging. Furthermore, when multiple abnormal events occur simultaneously, each event must be processed independently, which leads to a substantial increase in latency. Hence, our future studies will aim to enhance to the efficiency of the C-VAD in handling multiple abnormal events simultaneously.
(a) Anomaly event: jaywalking#

(b) Anomaly event: driving outside lane#

(c) Anomaly event: people and car accident#

(d) Anomaly event: walking drunk#
Figure S4. Anomaly detection in complex scenarios. Results with and without the inclusion of context are presented.
