

CALLM: Cascading Autoencoder and Large Language Model for Video Anomaly Detection#
1 st Apostolos Ntelopoulos Dept. of Electronic Systems Aalborg University Aalborg, Denmark [email protected]
Abstract—This paper introduces a new approach using a 3D Deep Autoencoder and a Large Visual Language Model (LVLM) to bridge the gap between video data and multi-modal models for Video Anomaly Detection. The study explores the limitations of previous architectures, particularly their lack of expertise when encountering out-of-distribution instances. By integrating an autoencoder and an LVLM in the same pipeline, this method predicts an abnormality’s presence and provides a detailed explanation. Moreover, this can be achieved by employing binary classification and automatically prompting a new query. Testing reveals that the inference capability of the system offers a promising solution to the shortcomings of industrial models. However, the lack of high-quality instruction-follow video data for anomaly detection necessitates a weakly supervised method. Current limitations from the LLM domain, such as object hallucination and low physics perception, are acknowledged, highlighting the need for further research to improve model design and data quality for the video anomaly detection domain.
Keywords—cascade, video, anomaly, detection, autoencoder, multimodal, LLM
I. INTRODUCTION#
In the past few years, large vision-language models have attempted to connect multiple modalities and progressively leverage the power of existing LLMs as their semantic power in textual form. Moreover, the recent approaches in video language models such as Video-LLaMA [1], VideoBERT [2], Video-ChatGPT [3], Video-LLaVA [4] and MiniGPT4Video [5] aim to solve complex tasks including as text-tovideo retrieval, video question and answering by utilizing a pretrained visual backbone and further align it with the frozen weights of an LLM, typically through the integration of videocaption data. On the other hand, video anomaly detection is a well-researched topic which involves identifying events that deviate from what is commonly observed. Classic video anomaly detection algorithms include motion-detection [6] [7] [8], temporal-spatial feature outliers [9] [10] [11] [10] or through skeleton trajectories [12] [13] [14]. However, despite the existing performance of the previously mentioned techniques to achieve adequate accuracy and quantify uncertainty, they often falter in detecting events that lie beyond the scope
979-8-3315-4184-2/24/$31.00 ©2024 IEEE
2 nd Kamal Nasrollahi Visual Analysis & Perception Lab Aalborg University & Milestone Systems Copenhagen, Denmark [email protected] of their training data, resulting in out-of-distribution errors. Thus, this paper explores a new way to address this limitation by testing the possible application of video language in connection with a baseline system.
The main contributions of this work are as follows:
- A novel architecture that integrates a cascade system combining a simple one-class classification (OCC) network with a Large Video-Language Model.
- A weak-supervised method for extracting video caption data from a pre-trained model, along with a technique for injecting pseudo-instructions to improve performance in downstream tasks.
- A comprehensive investigation into the capabilities of a state-of-the-art (SoTA) Video-Language Model for video anomaly detection, providing new insights and benchmarks for future research.
II. RELATED WORK#
VadCLIP: Adapting Vision-Language Models for Weakly Supervised Video Anomaly Detection
Recently, a work named VadCLIP [15] investigated the application of a pre-trained language-image model CLIP [16] to make use of the fine-grained dependencies between text and images with weak-supervised learning, producing a novel mechanism for extracting video-level labels. Particularly, it outperformed other prior weak-supervised models by introducing two core modules for video anomaly detection; a local module which captures the local features using a transformer encoder layer on top of the textual features coming from the frozen image encoder CLIP on an equal-size window, overlapping over the temporal dimension; and a global module which computes the relation between video frames. The prior module extracts the local features without information aggregation over the windows, whereas the subsequent module apprehends the global information between the video frames. It consists of a lightweight Graph Convolutional Network (GCN) which calculates the frame-wise cosine similarity to build its adjacency matrix of the GCN and capture the global temporal dependencies between the frame-level video features.
The frame-wise cosine similarity to calculate the adjacency matrix Hs Hsim is presented as follows:
where H sim is the adjacency matrix of the GCN and Xlis the frame-level video feature obtained from a local module.
Video Anomaly Detection and Explanation via Large Language Models
Another research paper on Video Anomaly Detection proposed the addition of a Long-Term Context Module (LTC) along with a pre-trained LLM to enhance the performance in detecting anomalies in long videos compared to short or normal videos, while also enabling the generation of textual explanations for events [17]. The process begins by dividing the input video into m-segments, followed by clip-level feature extraction using a Video Encoder (VE) based on a foundational model i.e. BLIP-2 [18], which is trained on a diverse corpus of large images and videos. Next, a simple anomaly prediction model is co-trained with the LTC module, which includes the clip-level features with anomaly scores to build the anomaly prompt module, which generates text that is conditioned on the video content and presents accordingly the anomaly status. The LTC module collects these clip-level features from the VE and updates them online while stacking them into a concatenated list. The normal list is denoted as N = n j , whereas these with high anomaly scores as A = aj with j = 1 , 2, . . . , K representing the input clip each time. These are simultaneously updated based on each clip anomaly score and aggregated via cross-attention with the pre-trained VE feature to prevent catastrophic forgetting after the fine-tuning stage. Therefore, when a new video is introduced in the system, the VE will handle the feature extraction for the LTC to update the content of the lists immediately with the new anomaly scores. The final system will be able to describe a video and pinpoint the timestamp of the abnormal incident.
III. METHOD#
The cascade system aims to deploy a 3D autoencoder and empower it with video-language understanding as an auxiliary mechanism. As depicted in Figure 1, the cascade consists of two separate stages, the 3D autoencoder and the fine-tuned Video-LLaMA [19]. In this section, the overall architecture is described, as well as the training goals through the different stages.
Fig. 1. The video is divided into individual frames. These frames are processed by the AE to decide whether to proceed to generate the final prediction with Video-LLaMA.

A. 1st Stage. 3D Autoencoder#
After processing an input video into individual frames, a 3D Autoencoder is implemented to classify each individual frame based on a manual selected threshold. It has been shown in various studies [20] [21] [22] [23] [24] [25] that deep autoencoders are able to comprehend the pattern from the low-dimensional space of the training data and reconstruct an approximation of a new image using the pre-trained weights. This capability is leveraged in the anomaly detection domain since evaluating the reconstruction error, makes it feasible to classify an event if it deviates from the normal. Furthermore, in the video domain, it is necessary to preserve the temporal information that is included. Thus, a 3D Autoencoder is adopted [26] [21] employing the time as the third dimension. AE is trained separately, learning the distribution of the training dataset and minimizing the Mean Squared Error (MSE) loss as follows:
where N is the total number of pixels of the video frame, xi the true value for the i-th pixel and xˆ ˆ i the predicted value for the i-th pixel. Essentially, the autoencoder has a bottleneck architecture which consists of the same number of layers in the encoder and decoder respectively [27]. For the video anomaly detection task, the implemented autoencoder applies 3D convolution over the input video frame and 3D batch normalization to prevent vanishing/exploding gradient issues at the beginning of the training. To capture higher-level patterns during reconstruction, the Tanh activation function is used instead of ReLU in the last layer of the decoder module, since it is able to extract more complex patterns in the latent space.
B. 2nd Stage. Video-Language Branch#
A video language model, adapted from Video-LLaMA [1], was chosen to process instances that exceeded the anomaly score threshold from the previous stage. Since the cost of pretraining and fine-tuning an LLM is indeed in many cases prohibitive, this method utilizes the alignment of the two frozen modules namely a Visual Encoder [18] and a pre-trained LLM [28] [29]. Specifically, the Visual Encoder consists of a ViT [30] and a Query-Transformer to align the text and image domain [18]. The share of communication between the text and visual transformer that the Q-former consists of, will be able to give a new set of queries to the model and align the frozen modules, as shown in Figure 2.
Fig. 2. Flow Diagram. A pre-trained Image Encoder processes an input image, whereas the Q-former bootstraps the vision-language learning by connecting the two frozen models.

Fig. 3. Video-Language Branch. The video frames are processed from a frozen Visual Encoder which extracts the video frame features. Then, positional embeddings are injected to add temporal information into video frames.
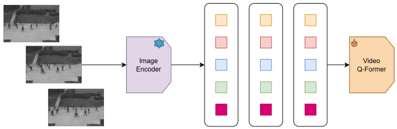
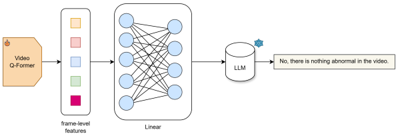
Fig. 4. Following the training of linear layers for frame-level embeddings match the text embeddings’ dimension. Finally, a binary answer of yes/no is given from the frozen LLM module conditioned on the video input.
IV. EXPERIMENT#
The performance comparison follows for each stage accordingly. A baseline is formulated as a standalone 3D autoencoder trained on each downstream dataset. The ensemble method is investigated afterwards presenting both frame-level and videolevel performance.
A. Baseline Method#
This approach consists of the 3D Autoencoder trained only on normal samples of datasets targeted for the video surveillance anomaly detection including CUHK Avenue Dataset [31], Ped2 [32], and ShanghaiTech [33]. The testing split of these datasets includes abnormal moving patterns and behaviour whereas CUHK Avenue is known to be harder to be correctly classified from the network due to the vague video content. The input sequence X for the autoencoder network has a shape of 16 x 1 x 256 x 256, where the number of frames, number of channels, height, and width of the video frames of the input sequence are presented. Thereafter, the decoder produces a reconstructed sequence of the same shape. The final anomaly score is derived from the Peak-Singal-toNoise-Ratio (PSNR) which measures the reconstructed frame quality compared to the true image. For training purposes, the L2 loss is calculated across all 16 frames, but only the 9th frame of the sequence is stored for the PSNR and anomaly score calculation.
Fig. 5. Initial system architecture. As a baseline was selected a VAD framework that outputs the anomaly score and depending on the threshold determines an anomaly or not.

TABLE I 3D DEEP AUTOENCODER
| Dataset | Baseline | MULDE [34] | SSTML [35] | MSMA [36] |
|---|---|---|---|---|
| CUHK Avenue | 80.46 % | 94.3 % | 91.5 % | 90.2 % |
| Ped2 | 91.19 % | 99.7 % | 97.5 % | 99.5 % |
| ShanghaiTech | 70.84 % | 86.7 % | 82.4 % | 84.1 % |
a Comparative Results of the baseline on the frame-level AUCF . The best results were chosen.
B. Cascading Autoencoder and Video-LLaMA#
A weakly supervised method is adopted by creating captions for the video-text alignment, which are fed to the fine-tuning process. BLIP-2 was utilized to extract in a zero-shot manner the frame representation (Fig. 6), where pseudo-instructions were injected afterwards to fine-tune Video-LLaMA on the downstream task of video anomaly detection.
Fig. 6. Selected examples of zero-shot caption generation with BLIP-2. The images are derived from datasets including ShangaiTech, UCSD Ped2, CUHK Avenue.

Particularly, phrases for the instruction-follow alignment from the CUHK Avenue Dataset include:
Caption: List of injected instruction-follow data:
- “This is abnormal. Someone is moving strangely in the wrong direction.”
- “This is abnormal. Someone is running.”
- “This is abnormal. A cyclist should not be there.”
These pseudo-instructions combined only with the testing videos that are labelled as abnormal, will be finally added for the 2nd training stage along with the general-purpose datasets LLaVA [37] [38] [39], MiniGPT-4 [40] [41] and VideoChat
[42] [43]. Finally, the accuracy comparison as shown in Table II, shows that adequate performance of the cascade system to classify a video without the requirement of being previously trained on the selected dataset i.e. Ped2 and ShanghaiTech. The results describe the video-level accuracy score, as VideoLLaMA samples uniformly 8 frames in a video and extract the video-level representation.
TABLE II CASCADE ACCURACY COMPARISON
| Dataset | 0-shot | 1-shot |
|---|---|---|
| CUHK Avenue | 9.52 | 33.33 |
| Ped2 | 8.33 | 66.66 |
| ShanghaiTech | 22.43 | 64.86 |
a Accuracy comparison within zero-shot and fine-tuning inference.
This table describes the video-level performance.
V. DISCUSSION#
Video-language models are a relevantly recent topic and can serve as a general-purpose tool in multiple different application areas. High-quality instruction-follow data plays a major role in reaching the capabilities of other models. It is remarkable that even in a zero-shot scenario, numerous actions observed in the testing data, such as throwing paper or navigating a university campus, can be accurately distinguished by the cascade system, but still not predict the true label correctly. Nevertheless, future research should address object hallucination in the frozen LLM and work on enhancing the model’s physics perception by incorporating more robust datasets and refining model architectures.
VI. FUTURE WORK#
To address the acknowledged problems in this paper, extensive research should be done on multimodal LLMs, training in a new manner the pretrained language-visual model while also fine-tuning the application task’s domain knowledge effectively. Utilizing keywords extracted from actions and objects could potentially enhance the efficiency of the cascade method, while objective metrics such as CHAIR [44] can objectively measure the LLM hallucination.
VII. CONCLUSION#
In this study, experimentation was conducted on the implementation of the cascade system alongside the recent breakthrough of Large Visual Language Models. Although the performance is currently limited within the Video Anomaly Detection domain, there is significant potential for improvement. Acquiring high-quality video-to-caption data could equip the model with the necessary knowledge to fine-tune according to the downstream task by learning the correlations between video-level representations and textual embeddings. This could not only have the potential to boost the model performance, as evidenced in related works but also to offer valuable insights to users analyzing surveillance footage.
REFERENCES#
[1] H. Zhang, X. Li, and L. Bing, “Video-llama: An instruction-tuned audio-visual language model for video understanding,” arXiv preprint arXiv:2306.02858, 2023.
[2] C. Sun, A. Myers, C. Vondrick, K. Murphy, and C. Schmid, “Videobert: A joint model for video and language representation learning,” in Proceedings of the IEEE/CVF international conference on computer vision , 2019, pp. 7464–7473.
[3] M. Maaz, H. Rasheed, S. Khan, and F. S. Khan, “Video-chatgpt: Towards detailed video understanding via large vision and language models,” arXiv preprint arXiv:2306.05424, 2023.
[4] B. Lin, B. Zhu, Y. Ye, M. Ning, P. Jin, and L. Yuan, “Video-llava: Learning united visual representation by alignment before projection,” arXiv preprint arXiv:2311.10122, 2023.
[5] K. Ataallah, X. Shen, E. Abdelrahman, et al. , “Minigpt4-video: Advancing multimodal llms for video understanding with interleaved visual-textual tokens,” arXiv preprint arXiv:2404.03413, 2024.
[6] D. Samariya and A. Thakkar, “A comprehensive survey of anomaly detection algorithms,” Annals of Data Science, vol. 10, no. 3, pp. 829–850, 2023.
[7] T.-N. Nguyen and J. Meunier, “Anomaly detection in video sequence with appearance-motion correspondence,” in Proceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 1273–1283.
[8] S. Wang, E. Zhu, J. Yin, and F. Porikli, “Video anomaly detection and localization by local motion based joint video representation and ocelm,” Neurocomputing, vol. 277, pp. 161–175, 2018.
[9] Y. Chang, Z. Tu, W. Xie, et al., “Video anomaly detection with spatio-temporal dissociation,” Pattern Recognition, vol. 122, p. 108 213, 2022.
[10] Y. Zhao, B. Deng, C. Shen, Y. Liu, H. Lu, and X.-S. Hua, “Spatio-temporal autoencoder for video anomaly detection,” in Proceedings of the 25th ACM international conference on Multimedia, 2017, pp. 1933–1941.
[11] R. Tudor Ionescu, S. Smeureanu, B. Alexe, and M. Popescu, “Unmasking the abnormal events in video,” in Proceedings of the IEEE international conference on computer vision, 2017, pp. 2895–2903.
[12] R. Morais, V. Le, T. Tran, B. Saha, M. Mansour, and S. Venkatesh, “Learning regularity in skeleton trajectories for anomaly detection in videos,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 11 996–12 004.
[13] A. Flaborea, L. Collorone, G. M. D. Di Melendugno, S. D’Arrigo, B. Prenkaj, and F. Galasso, “Multimodal motion conditioned diffusion model for skeletonbased video anomaly detection,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 10 318–10 329.
[14] A. Flaborea, G. D’Amely, S. D’Arrigo, M. A. Sterpa, A. Sampieri, and F. Galasso, “Contracting skeletal kinematics for human-related video anomaly detection,” arXiv preprint arXiv:2301.09489, 2023.
[15] P. Wu, X. Zhou, G. Pang, et al., “Vadclip: Adapting vision-language models for weakly supervised video anomaly detection,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 38, 2024, pp. 6074– 6082.
[16] A. Radford, J. W. Kim, C. Hallacy, et al., “Learning transferable visual models from natural language supervision,” in International conference on machine learning, PMLR, 2021, pp. 8748–8763.
[17] H. Lv and Q. Sun, “Video anomaly detection and explanation via large language models,” arXiv preprint arXiv:2401.05702, 2024.
[18] J. Li, D. Li, S. Savarese, and S. Hoi, “Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models,” in International conference on machine learning, PMLR, 2023, pp. 19 730–19 742.
[19] H. Zhang, X. Li, and L. Bing, “Video-llama: An instruction-tuned audio-visual language model for video understanding,” arXiv preprint arXiv:2306.02858, 2023. [Online]. Available: https://arxiv.org/abs/2306.02858.
[20] E. T. Nalisnick, A. Matsukawa, Y. W. Teh, D. Gor¨ ¨ ur, and B. Lakshminarayanan, “Do deep gener- ¨ ¨ ative models know what they don’t know?” ArXiv , vol. abs/1810.09136, 2018.
[21] D. Gong, L. Liu, V. Le, et al., “Memorizing normality to detect anomaly: Memory-augmented deep autoencoder for unsupervised anomaly detection,” 2019 IEEE/CVF International Conference on Computer Vision (ICCV) , pp. 1705–1714, 2019.
[22] Z. Chen, C. K. Yeo, B. S. Lee, and C. T. Lau, “Autoencoder-based network anomaly detection,” in 2018 Wireless telecommunications symposium (WTS) , IEEE, 2018, pp. 1–5.
[23] J. An and S. Cho, “Variational autoencoder based anomaly detection using reconstruction probability,” Special lecture on IE, vol. 2, no. 1, pp. 1–18, 2015.
[24] C. Zhou and R. C. Paffenroth, “Anomaly detection with robust deep autoencoders,” in Proceedings of the 23rd ACM SIGKDD international conference on knowledge discovery and data mining, 2017, pp. 665–674.
[25] Z. Cheng, S. Wang, P. Zhang, S. Wang, X. Liu, and E. Zhu, “Improved autoencoder for unsupervised anomaly detection,” International Journal of Intelligent Systems , vol. 36, no. 12, pp. 7103–7125, 2021.
[26] M. Astrid, M. Z. Zaheer, J.-Y. Lee, and S.-I. Lee, “Learning not to reconstruct anomalies,” in BMVC , 2021.
[27] G. E. Hinton and R. R. Salakhutdinov, “Reducing the dimensionality of data with neural networks,” science , vol. 313, no. 5786, pp. 504–507, 2006.
[28] W.-L. Chiang, Z. Li, Z. Lin, et al. , Vicuna: An opensource chatbot impressing gpt-4 with 90%* chatgpt quality, 2023.
[29] F. Bordes, R. Y. Pang, A. Ajay, et al., “An introduction to vision-language modeling,” arXiv preprint arXiv:2405.17247, 2024.
[30] Q. Sun, Y. Fang, L. Wu, X. Wang, and Y. Cao, “Evaclip: Improved training techniques for clip at scale,” arXiv preprint arXiv:2303.15389, 2023.
[31] C. Lu, J. Shi, and J. Jia, “Abnormal event detection at 150 fps in matlab,” in Proceedings of the IEEE international conference on computer vision, 2013, pp. 2720–2727.
[32] W. Li, V. Mahadevan, and N. Vasconcelos, “Anomaly detection and localization in crowded scenes,” IEEE transactions on pattern analysis and machine intelligence, vol. 36, no. 1, pp. 18–32, 2013.
[33] W. Liu, W. Luo, D. Lian, and S. Gao, “Future frame prediction for anomaly detection–a new baseline,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 6536–6545.
[34] J. Micorek, H. Possegger, D. Narnhofer, H. Bischof, and M. Kozinski, “Mulde: Multiscale log-density estimation via denoising score matching for video anomaly detection,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 18 868–18 877.
[35] M.-I. Georgescu, A. Barbalau, R. T. Ionescu, F. S. Khan, M. Popescu, and M. Shah, “Anomaly detection in video via self-supervised and multi-task learning,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 12 742–12 752.
[36] A. Mahmood, J. Oliva, and M. Styner, “Localizing anomalies via multiscale score matching analysis,” arXiv preprint arXiv:2407.00148, 2024.
[37] H. Liu, C. Li, Q. Wu, and Y. J. Lee, Visual instruction tuning, 2023.
[38] H. Liu, C. Li, Y. Li, and Y. J. Lee, Improved baselines with visual instruction tuning, 2023.
[39] H. Liu, C. Li, Y. Li, et al. , Llava-next: Improved reasoning, ocr, and world knowledge, 2024. [Online]. Available: https://llava-vl.github.io/blog/2024-01-30llava-next/.
[40] J. Chen, D. Zhu, X. Shen, et al., “Minigpt-v2: Large language model as a unified interface for vision-language multi-task learning,” arXiv preprint arXiv:2310.09478 , 2023.
[41] D. Zhu, J. Chen, X. Shen, X. Li, and M. Elhoseiny, “Minigpt-4: Enhancing vision-language understanding with advanced large language models,” arXiv preprint arXiv:2304.10592, 2023.
[42] K. Li, Y. He, Y. Wang, et al., “Videochat: Chat-centric video understanding,” arXiv preprint arXiv:2305.06355 , 2023.
[43] Y. Wang, K. Li, Y. Li, et al., “Internvideo: General video foundation models via generative and discriminative learning,” arXiv preprint arXiv:2212.03191, 2022.
[44] P. Kaul, Z. Li, H. Yang, et al., “Throne: An object-based hallucination benchmark for the free-form generations of large vision-language models,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 27 228–27 238.