

Multimodal VAD: Visual Anomaly Detection in Intelligent Monitoring System via Audio-Vision-Language#
Dicong Wang , Graduate Student Member, IEEE, Qilong Wang , Senior Member, IEEE , Qinghua Hu , Senior Member, IEEE, and Kaijun Wu , Member, IEEE
Abstract—The deep learning-based anomaly detection methods using visual sensors generally rely on a single modality or variants as raw signal inputs, which severely limits expressiveness and adaptability. The evolution of multimodal and visual-language pretrained models is shaping new possibilities in video anomaly detection (VAD). So, how to efficiently leverage them to achieve reliable multimodal VAD presents a significant challenge worth investigating. In this work, we propose a novel dual-stream multimodal VAD network, which integrates coarse-grained and fine-grained streams combining video, audio, and text modalities. First, in the coarse-grained stream, we perform cross-modal fusion of audio features with temporally modeled visual features, utilizing contrastive optimization to achieve more accurate coarse-grained results. In the fine-grained stream, we constructed abnormal-aware context prompts (ACPs) by integrating visual information and prior knowledge related to anomalous events into the text modality. Through the “coarse-support-fine” strategy, we further enhanced the model’s ability to discriminate fine-grained anomalies. Our method achieved optimal performance in experiments on two large-scale anomaly datasets, demonstrating its effectiveness and superiority. It supports the development of highly robust intelligent monitoring systems and promotes the potential applications of multimodal VAD across industrial monitoring, public safety, smart cities, and so on.
Index Terms—Abnormal-aware context prompts (ACPs), multimodal, video anomaly detection (VAD), weakly supervision.
I. INTRODUCTION#
T HE arrival of Industry 4.0 marks the transformation of manufacturing, driving the development of “intelligent
Received 18 November 2024; revised 25 March 2025; accepted 28 May 2025. Date of publication 16 June 2025; date of current version 20 June 2025. This work was supported in part by the National Natural Science Foundation of China under Grant 62276186 and Grant U23B2049; in part by the Natural Science Foundation Key Project of Gansu Province under Grant 23JRRA860; in part by the Inner Mongolia Key Research and Development and Achievement Transformation Project under Grant 2023YFDZ0043, Grant 2023YFDZ0054, and Grant 2023YFSH0043; in part by the Key Research and Development Project of Lanzhou Jiaotong University under Grant ZDYF2304; and in part by the Key Talent Project of Gansu Province. The Associate Editor coordinating the review process was Dr. Jianbo Yu. (Corresponding authors: Qilong Wang; Kaijun Wu.)
Dicong Wang is with the College of Intelligence and Computing, Tianjin University, Tianjin 300350, China, and also with the School of Electronics and Information Engineering, Lanzhou Jiaotong University, Lanzhou 730070, China (e-mail: wangdc [email protected]).
Qilong Wang and Qinghua Hu are with the College of Intelligence and Computing, Tianjin University, Tianjin 300350, China (e-mail: [email protected]; [email protected]).
Kaijun Wu is with the School of Electronics and Information Engineering, Lanzhou Jiaotong University, Lanzhou 730070, China (e-mail: [email protected]).
Digital Object Identifier 10.1109/TIM.2025.3578702
detection/monitoring systems” by integrating digital technologies, such as machine learning (ML), the Internet of Things (IoT), and cyber-physical systems into visual anomaly detection. Following this, Industry 5.0 further advanced the application of digital technologies and intelligent devices, enabling comprehensive monitoring and refined management of production processes. This effectively enhanced production efficiency and reduced costs for enterprises, further propelling the development of intelligent detection and monitoring systems. Surveillance cameras are increasingly used in industrial fault detection [1] , [2], intelligent security monitoring [3] , [4] , [5], and production line defect detection [6] , [7] , [8]. Nevertheless, the present automated anomaly detection technologies lag behind, resulting in suboptimal utilization of surveillance equipment and limiting their potential. Drawing inspiration from the natural way humans watch videos, video anomaly detection (VAD) relies not only on visual information but also on audio and others (such as captions or text), which are indispensable for creating a complete perceptual experience. In smart cities, the precision and comprehensiveness required by video surveillance systems make multimodal learning especially necessary. In intelligent security systems, the ability to identify and respond to various anomalous behaviors and emergencies is critical, especially in areas, such as public safety, traffic management, and emergency response. Introducing multimodal information can significantly reduce reliance on unimodal data, effectively overcoming issues, such as information loss and incomplete representation that may arise from using a single modality, thereby enabling the model to analyze anomalies from multiple perspectives [9]. Therefore, constructing a multimodal VAD network is not only essential for enhancing the intelligence of security systems but also plays a vital role in advancing the development of smart cities. It assists urban managers in real-time, comprehensive monitoring and management of urban conditions, improving city safety and quality of life.
According to the industry definition of anomalous events, VAD methods can be roughly categorized into unsupervised VAD and weakly supervised VAD. In the unsupervised paradigm, VAD models are trained solely on normal data, treating any data that deviates from the normal distribution as anomalous. Numerous excellent studies have emerged under the unsupervised paradigm [10] , [11] , [12] , [13] , [14] , [15] , [16] , [17], including those based on reconstruction [10] , [15] ,
1557-9662 © 2025 IEEE. All rights reserved, including rights for text and data mining, and training of artificial intelligence and similar technologies. Personal use is permitted, but republication/redistribution requires IEEE permission.
See https://www.ieee.org/publications/rights/index.html for more information.
Fig. 1. Distribution of modalities in existing methods. (a) Focused on using unimodal images or variants for VAD. (b) Some multimodal methods combine images with audio or text. (c) Ours integrates image, audio, and text modalities, capturing subtle features of anomalies and improving model adaptability and reliability.
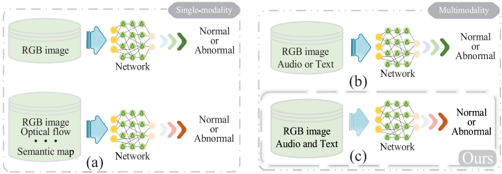
prediction [12] , [13], and so on. However, the main limitation of the aforementioned methods is the singularity of modalities and the lack of anomalous diversity. Despite the existence of various modalities, such as optical flow, depth maps, and semantic maps, these are still variants or derivatives based on RGB images, which, broadly speaking, can be considered as the same modality [as shown in Fig. 1(a)]. Weakly supervised VAD (WSVAD) has garnered increasing attention in recent years due to its broad application prospects. Compared to unsupervised methods, weakly supervised methods have several notable advantages: 1) due to the simultaneous presence of both anomalous and normal data, the model can learn richer discriminative representations; 2) WSVAD leverages coarse-grained video-level labels to achieve a good tradeoff between performance and efficiency at a lower cost; and 3) the production of large-scale anomaly datasets becomes feasible. Currently, most weakly supervised methods typically formalize it as multiple instance learning (MIL) [18] , [19] , [20] , [21] , [22] , [23] , [24] , [25] , [26] , [27] , [28] , [29]. As a mainstream research paradigm in WSVAD, MIL has led to the emergence of various innovative ideas and methods in this field. Sevetlidis et al. [19] proposed a method that integrates anomaly information through weighted training, aimed at enhancing detection performance in weakly supervision, particularly demonstrating noteworthy results in scenarios with sparse labeled data. Lv et al. [23] proposed a bias-free anomaly detector through invariant learning of confident and ambiguous segments with different contextual biases, effectively reducing bias issues caused by contextual changes during the detection process. Given the scarcity of anomalous data and high labeling costs, continuous development and efforts have shown that incorporating multimodal information effectively reduces dependence on single-modal data, mitigates potential information loss, and makes VAD tasks more comprehensive [2] , [7]. Meanwhile, with the notable achievements of visionlanguage pretraining (VLP) models across various tasks, an increasing number of researchers are exploring how to transfer the semantic knowledge learned by these models into VAD. The strong ability of VLP models to capture the complex multimodal relationships between vision and language offers new possibilities for multimodal VAD [24] , [25] , [27]. However, most current methods primarily focus on the combination of video with audio or text [as shown in Fig. 1(b)], failing to fully leverage the potential advantages of multimodalities. In our work, we organically integrate video, audio, and textual information [as shown in Fig. 1(c)], fully leveraging the synergistic and complementary effects of multimodal data to more comprehensively capture and describe the characteristics of anomalous events.
Based on the above analysis, we propose a multimodal two-stream VAD network capable of processing visual, audio, and textual modalities. Specifically, we first perform temporal modeling on visual information to capture dynamic changes and spatial features in the video. Subsequently, we conduct cross-modal fusion of the visual features and the encoded audio signals to enhance the perception and understanding of anomalous events. The fused features are then utilized for coarse-grained frame-level classification to preliminarily distinguish between anomalous and normal events. At the same time, we introduce a contrastive constraint to strengthen the model’s discriminative capacity and resilience, which further enhances subsequent fine-grained anomaly detection. For the fine-grained stream, we design abnormal-aware context prompts (ACPs), encoding them into a text encoder to generate corresponding text embeddings. By calculating the similarity matrix between the text embeddings and the visual embeddings, we further improve the model’s performance in fine-grained anomaly detection.
In summary, the main contributions of this article are as follows.
- Effective Fusion of Multimodal Data: By effectively integrating heterogeneous source information—visual, audio, and textual—we achieve mutual supplementation of information, capturing richer, more comprehensive, and diverse feature representations.
- Dual-Stream Network With Coarse and Fine Granularity: The coarse-grained stream via audiovisual fusion, contrastively optimized, yields a global perspective. The fine-grained stream via APCs, the “coarse-support-fine” strategy, offers anomalous detail.
- Abnormal-Aware Context Prompt (ACP): Incorporating anomalous visual information and prior knowledge into the textual modality improves the recognition and analysis of fine-grained anomalous behaviors.
- Extensive Experimental Validation and SOTA Performance: We systematically evaluated its effectiveness and adaptability on two large benchmarks, achieving optimal performance across multiple metrics.
The organization of this article is as follows. In Section II , we review the research progress related to VAD. In Section III , we elaborate on the multimodal VAD method we proposed. In Section IV, we conduct a series of experiments to validate and analyze the proposed method. Finally, Section V concludes our work and provides an outlook on future research.
II. RELATED WORK#
A. Video Anomaly Detection#
Early VAD was predominantly based on unsupervised methods [11] , [29] , [30]; however, these approaches are limited in capturing subtle behavioral changes and in thoroughly understanding anomalous events, thus underscoring the urgent
need to incorporate anomaly-related knowledge [26] , [31]. The continuous advancements in deep learning have driven the evolution of VAD, gradually shifting research toward weakly supervised anomaly detection. Current weakly supervised methods can generally be categorized into two main types: one adopts a two-stage self-training strategy, while the other is a single-stage method based on MIL. Since the introduction of the MIL method, it has been continuously developed and optimized, attracting widespread attention. The related research focuses on leveraging spatiotemporal contextual information and motion features, emphasizing the overall temporal continuity of anomalous events and accurately capturing the subtle boundary changes between anomalies and normal instances [18] , [29] , [32]. With the continuous advancement and evolution of VAD, multimodal approaches have gradually emerged. These methods are not only model based on traditional visual information but also integrate other modalities, such as audio and text. These modalities’ complementarity effectively compensates for the limitations that may exist in single modality, enabling capturing anomalous behaviors and better interpreting scenes through cross-modal fusion [24] , [26] , [33] , [34]. Meanwhile, anomaly detection methods based on large language models (LLMs) and vision-language models (VLMs) have also begun to attract the attention and exploration of researchers [35] , [36]. These cutting-edge technologies and innovative ideas open novel opportunities and challenges in visual anomaly detection.
B. LLMs and VLMs on VAD#
In recent years, vision-language pretraining models have not only demonstrated remarkable progress in tasks, such as image captioning [37], visual question answering [38], and imagetext matching [39] , [40], but have also played a crucial role in industrial monitoring and measurement. By integrating visual sensor data with textual descriptions, these models enhance the accuracy of anomaly detection [19], fault diagnosis [1] , and intelligent decision-making systems, providing critical technological support for intelligent industrial production and quality control. Kim et al. [41] used ChatGPT to generate textual descriptions of normal and abnormal elements, thus providing the textual data required for training CLIP. However, this approach has a human-in-the-loop issue, necessitating a certain degree of manual intervention to optimize output according to specific application contexts. Zanella et al. [35] exploited the existing VLM to generate textual descriptions for each test frame and designed specific prompt mechanisms to unlock the capabilities of LLM in temporal aggregation and anomaly score estimation, making them effective detectors. Du et al. [9] employed visual language large models (VLLMs) to uncover and capture the key clues of anomalous behavior and establish a logical chain of causality, thereby accurately identifying and inferring the occurrence process of anomalous events. In this article, we will further explore how to effectively transfer the semantic understanding and cross-modal matching advantages demonstrated by the large-scale VLM CLIP in processing image and text information to the VAD task, providing new insights and directions in subsequent research.
C. Multimodality on VAD#
With the rapid development in areas, such as image/video understanding [42], pattern recognition [30] , [31], text-toimage generation [43], and speech recognition [44], we are closer than ever to achieve the integration and unification of multimodal learning [45]. Compared to unimodal methods, multimodal VAD integrates heterogeneous source data—such as visual, audio, and textual information—that exhibit significant differences in representation and distribution. This enhances capabilities in information fusion and representation while offering unique research mechanisms and challenges to the VAD community due to the latent connections and interactions among modalities [20] , [25] , [27] , [34] , [46] , [47]. Yu et al. [46] proposed a modality-aware contrastive multi-instance learning network with self-distillation, offering improved parameter efficiency, scalability, and effectiveness while resolving inconsistencies between audio and video events. Wu et al. [20] , [21] tackled the issues of limited scene diversity and modality insufficiency in prior datasets by constructing a large-scale audiovisual multimodal dataset called XD-Violence. This innovative work enriches the existing VAD data resources and greatly enhances the reliability and expansibility of VAD through the fusion of multimodal information. Zhang et al. [47] effectively corrected and refined the detection boundaries in the anomaly space by introducing multiple constraints and optimized the definition of the anomaly boundaries to better align with the requirements of practical applications. In contrast, our method integrates different types of data, including visual, audio, and textual information, to construct a richer and more multidimensional feature representation. This enhances the understanding and analysis of complex video content and aids in more comprehensive identification and interpretation of anomalous events.
III. METHODOLOGY#
A. Preliminaries#
First, given an untrimmed audiovisual sequence X = (x v , x a ), where x v represents video information and x a represents audio information, we segment the entire sequence into N segments x = {x v , x a } N i=1 and assign corresponding coarsegrained video-level labels y c ∈ {0 , 1}, where y c = 1 indicates the presence of anomalous events in x. We utilize off-theshelf pretrained networks as feature extractors to separately extract visual and audio information, obtaining visual features F v and audio features F a F a . Specifically, F v = {f v } N i=1 ∈ R L×d v and F a F a = {f a } N i=1 ∈ R L×d a , where f i v f i and f i a f i denote the video and audio features of the i-th segment, d v and d a represent the dimensions of the video and audio features, respectively, and L denotes the length of the video sequence X . In the MIL framework, we treat a video sequence as a bag and the audiovisual segments {x v , x a } n i=1 as instances.
B. Two-Stream Network#
In this article, we propose a dual-stream network for multimodal VAD, enhancing precision and generalization through the synergy of coarse-grained and fine-grained streams (refer to Fig. 2). The coarse-grained stream fuses visual
Fig. 2. Overview. We have constructed a dual-stream network capable of simultaneously processing image, audio, and text modalities, utilizing a “coarsesupport-fine” strategy to establish their interconnections. Through cross-modal audio-video fusion and contrastive constraints, we perform coarse-grained anomaly detection; concurrently, we introduce ACPs that are sensitive to anomalies to enhance the discriminative capability for fine-grained anomalous events.
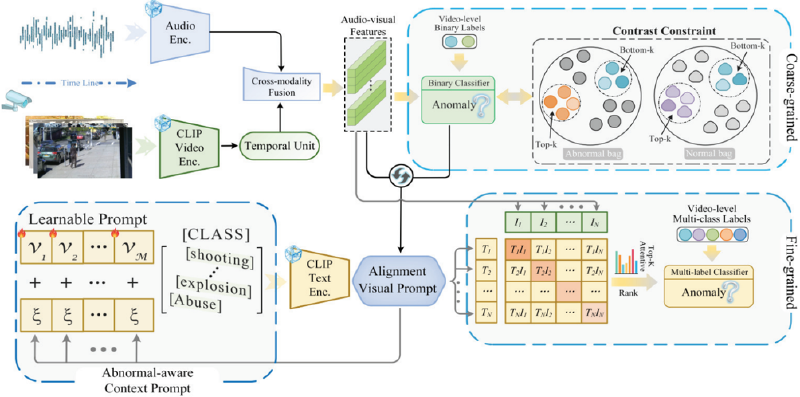
and audio signals to generate multimodal representations, facilitating effective detection of anomalies. A contrastive learning strategy further improves sensitivity by focusing on anomalous samples through positive-negative sample comparisons. In the fine-grained stream, we construct ACPs using learnable parameters, category information, and weighted coarse-grained fused features, enabling reliable identification of anomalies. This collaboration ensures comprehensive detection at both levels, showcasing robust generalization and sensitivity.
C. Coarse-Grained Stream#
- Temporal Modeling and Cross-Modal Fusion: During audio signal processing, we perform feature encoding to obtain audio features F
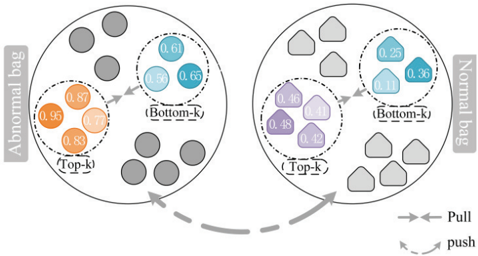
Fig. 3. Diagram of contrast constraint.
features
In the coarse-grained stream, the audio-visual features are processed through a binary classifier to obtain the coarsegrained anomaly confidence P c
where σ denotes the sigmoid function.
- Contrastive Constraint: To further explore the feature differences and interrelations between normal and abnormal videos, we propose an optimization method based on contrastive constraints, as shown in Fig. 3. Specifically, to accurately capture the feature differences between normal and abnormal videos, we introduce a video sequence partitioning strategy based on anomaly confidence p c . By conducting a
comparative analysis of feature segments in different score intervals, we reveal subtle abnormal patterns. First, we differentiate between normal and abnormal videos based on the anomaly confidence p c of each video sequence. When p c exceeds a threshold ε, the video sequence is classified as abnormal, denoted as Xa Xa ; when p c is below the threshold, it is classified as normal, denoted as Xn Xn . For abnormal sequences Xa Xa (i.e., p c > ε), we select the top k feature segments with the highest scores, forming an abnormal mini-bag B top-a min ⊂ {D a (m)} k m= 1 .
These feature segments generally represent more significant abnormal patterns, reflecting the model’s high-confidence predictions of anomalous events. Simultaneously, we also select the k lowest scoring feature segments, forming another abnormal mini-bag B bot-a min ⊂ {D a (m)} k m= 1 . These segments typically manifest as more or uncertain abnormal samples, which help the model capture potential fine-grained anomalies.
Similarly, for normal sequences Xn Xn (i.e., p c < ε), we adopt a similar partition strategy; first, we select the top-k feature segments with the highest scores to form the normal mini-bag B top-n min ⊂ {D n (m)} k m= 1 , which typically represent the characteristic features of normal videos. Then, we select the bottom-k feature segments with the lowest scores to form the normal mini-bag B bot-n min ⊂ {D n (m)} k m= 1 to help the model recognize common or marginal features in normal videos.
Based on these partitions, we use the InfoNCE loss function as the optimization objective, constraining the model to focus more on the detailed contrast between anomalous and normal video sequences during training. This enables the model not only to effectively learn the latent structure within the data but also to enhance its perception and understanding of subtle yet important feature differences in video sequences, thereby improving its discriminative capability
D. Fine-Grained Stream#
- Abnormal-Aware Context Prompt (ACP): ACP aims to enhance visual representation by introducing anomaly-related semantic information, enabling more effective modeling of various anomaly patterns, as shown in Fig. 4. Specifically, discrete textual labels (such as robbery, fighting, shooting, etc.) are regarded as category identifiers. These labels serve as descriptive information for the target events and need to be encoded. We use the Tokenizer to process the textual labels, generating a high-dimensional embedding representation te tembed = Tokenizer(y t ), where y t represents the specific textual label, which contains key information related to the event. Next, the generated textual embedding tembed is combined with M learnable parameters vi. After concatenating the textual embedding with these learnable parameters, we obtain a new sentence embedding representation, as shown in the following:
Fig. 4. Diagram of ACP construction.
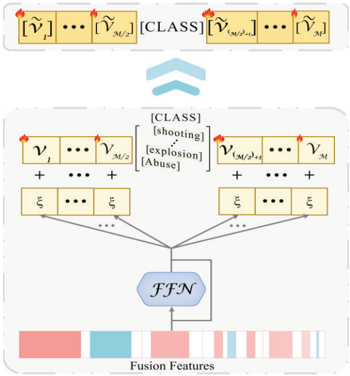
We believe that anomaly-conditional context embeddings can better adapt to the task requirements of multimodal VAD. To achieve this, we introduced a lightweight dynamically aligned visual prompt network (composed of a simple FFN and skip connection) to incorporate anomaly knowledge into each learnable prompt, enabling it with anomaly awareness. To be exact, we introduce vϑ(∗) = ξ, an alignment visual prompt network parameterized by ϑ, which fuses the anomalyweighted visual information with textual information. The output is then processed by vϑ(∗), and by adding this result to the existing context prompt, we obtain a context prompt with anomaly awareness
- Image-Text Registration: To further explore the potential of fine-grained anomaly detection, the anomaly scores generated by the coarse-grained stream are used as weighting factors, which are then combined with the fused multimodal audio-visual features to perform fine-grained detection. The focus is on regions or frames in the video where anomalies may exist, thereby enhancing the model’s sensitivity to anomaly details and its ability to discriminate them
Finally, we compute the similarity between the fused visual features F and the category embeddings T , resulting in a registration map M
E. Objective Function#
- Coarse-Grained Stream: In the coarse-grained stream, in addition to using the contrastive loss to enhance the discriminative ability between different feature representations, we further introduce a video-level classification loss. We calculate the binary cross-entropy loss function L c bce , between the video
prediction scores and their corresponding ground truth (GT) labels to optimize the model
- Fine-Grained Stream: In the fine-grained stream, we adopt an attention-based top-k mechanism to extend the vanilla MIL into a generalized MIL suitable for multiclass tasks. In particular, in the image-text alignment mapping matrix M , which represents the similarity between visual features and all class embeddings, we select the top-k similarity values for each category and average the similarities of the selected frames to quantify the alignment degree between the video and the current category. Through this process, we obtain a vector u = {u1 , . . . , uk}, which represents the similarity between the video and all categories. We expect the video and its paired text label to have the highest similarity score. The multiclass prediction is then carried out as follows:
where p f i represents the predicted confidence for the i-th class and τ is the temperature scaling hyperparameter. It is important to note that due to the dual-stream nature of the network architecture, each network branch with different granularities generates its own anomaly score. We take the larger of the two as the anomaly score for the entire network. Finally, we employ the fine-grained aligned binary cross-entropy loss L f bce . Additionally, we introduce an embedding constraint to ensure semantic consistency, thereby obtaining semantically rich anomaly-aware prompts. We quantify the differences in the feature space by calculating the cosine similarity between the normal embeddings and the embeddings of each anomaly class. Based on this similarity, we further define an embedding constraint loss L embed to regulate the organization of the embedding space, ensuring that normal embeddings are closely clustered, while anomaly embeddings maintain an appropriate distance from the normal embeddings
where t e 0n t embed represents the normal embeddings and t e 0a t embed represents the abnormal embeddings.
The final multimodal VAD loss function is the sum of the above loss functions
IV. EXPERIMENTS#
A. Datasets and Evaluation Metrics#
- Datasets: Our experiments were conducted on two large-scale datasets widely recognized in the VAD community: UCF-Crime [28] and XD-Violence [20]. UCF-Crime primarily consists of 1900 untrimmed real-world surveillance videos with a total duration of 128 h, where the number of abnormal and normal videos is roughly equal. Among these, 810
abnormal and 800 normal videos are used for training. These videos cover 13 types of real-world anomalies. XD-Violence mainly consists of YouTube videos from movies and outdoor scenes. It contains a total of 4854 untrimmed videos with audio and weakly labels, amounting to 217 h, with 2405 abnormal and 2349 normal videos, of which 1905 abnormal and 2049 normal videos are used for training. These videos are captured in diverse settings, such as handheld cameras, CCTV, movies, sports, and so on, covering six types of anomalous behaviors. 2) Evaluation Metrics: Following previous excellent works [21] , [24] , [27] , [46], we use frame-level average precision (AP) for XD-Violence and frame-level AUC, as well as AUC under only anomalous videos (AUC no-n ), for UCF-Crime. In addition, to ensure the comprehensiveness and standardization of the evaluation, we adhere to the standard evaluation protocols in the field of video action recognition [50], using mean AP (mAP) values under different intersection over union (IoU) thresholds, along with the average of overall mAP. The selection and application of these evaluation metrics not only render our results comparable and consistent but also provide a more comprehensive reflection of the model’s performance across various complex scenarios.
B. Implementation Details#
Following previous excellent works [20] , [24] , [60], we employed the pretrained CLIP (ViT-B/16) model to extract video and text features for both modalities. For audio features, we adopted the same feature extraction method as in prior works, using the VGGish audio extractor, which was pretrained on the YouTube dataset. Additionally, both the visual and audio features were aligned at a coarse-grained level. For hyperparameter settings, the batch sizes and total epochs for UCF-Crime and XD-Violence were set to 64 and 128 and 40 and 60, respectively. In (13) , λ1 was set to 0.1 and 0.15, and λ2 λ2 to 1e-1 and 2e-4, and Adam was used for optimization. Our network was implemented using PyTorch [51] and trained end-to-end on an NVIDIA GeForce RTX 3090 GPU.
C. Comparisons With State-of-the-arts#
- Result on UCF-Crime: Our evaluation results on UCFCrime are presented in Tables I and II. Overall, our method markedly outperforms unsupervised methods as well as other weakly supervised methods, regardless of whether these methods are based on I3D, VideoSwinTransformer, or other extractors. Specifically, in the coarse-grained aspect, as shown in Table I, our method exhibits a significant advantage, surpassing multiple existing methods, including UR-DMU [52] and so on. Although UR-DMU introduces two additional memory modules, which separately store abnormal and normal patterns to enrich feature representation, our method still achieves superior performance. Moreover, compared to VadCLIP [24], our method attains comparable results, with a gap of only 0.06%. This minimal difference further underscores the effectiveness and robustness of our approach in the challenging task of VAD. In the fine-grained aspect, as depicted in Table II , our method outperforms the current state-of-the-art works we compared. It is worth noting that although our coarse-grained
TABLE I COMPARISON WITH OTHER SOTA METHODS ON UCF-CRIME. BOLD INDICATES THE PERFORMANCE ACHIEVED BY OUR METHOD
TABLE II FINE-GRAINED COMPARISON WITH OTHER SOTA METHODS ON UCF-CRIME. BOLD INDICATES THE PERFORMANCE ACHIEVED BY OUR METHOD
performance does not reach the best level as VadCLIP, our fine-grained performance is superior. This indicates that our method achieves a more precise alignment with the anomalous time intervals than VadCLIP, which is mainly attributed to the incorporation of more anomaly-related information and knowledge into the model, allowing it to more accurately capture and identify subtle changes in abnormal events.
- Result on XD-Violence: Table III presents a comparison of the AP values between our method and the current state-ofthe-art methods. It is evident from Table III that our method performs exceptionally well in both unsupervised and weakly supervised methods and reaches optimal performance. Specifically, our method outperforms TPWNG [27], VadCLIP [24] , and PEL4VAD [25] by 2.64%, 1.81%, and 0.73%, respectively. The key to VadCLIP’s performance enhancement lies in its use of finer-grained class labels and the full utilization of the semantic representation capabilities of textual information. However, our method goes further by introducing an efficient anomaly-aware contextual prompt to deeply model anomalous scenes. Moreover, we integrate audio information,
TABLE III COMPARISON WITH OTHER SOTA METHODS ON XD-VIOLENCE. BOLD INDICATES THE PERFORMANCE ACHIEVED BY OUR METHOD
TABLE IV COMPARISON OF SOTA METHODS UNDER DIFFERENT MODALITIES ON XD-VIOLENCE. BOLD INDICATES THE PERFORMANCE ACHIEVED BY OUR METHOD
effectively assisting the model’s ability to capture anomalies. Although PEL4VAD also utilizes textual information and achieves results close to ours, its primary strength lies in the fine processing of visual features, which still shows some gaps compared to our method. In Table IV, we present a detailed comparative analysis of the state-of-the-art methods under different modality inputs. The results show that methods relying solely on the visual modality exhibit relatively average performance. In contrast, bimodal methods that incorporate audio signals (such as environmental sounds and event-related audio cues) or higher level semantic text information substantially improve performance. This indicates that by integrating additional modality information, the model is able to more comprehensively understand and analyze video content, thus
TABLE V FINE-GRAINED COMPARISON WITH OTHER SOTA METHODS ON XD-VIOLENCE. BOLD INDICATES THE PERFORMANCE ACHIEVED BY OUR METHOD
TABLE VI IMPACT OF DIFFERENT INPUT MODALITIES ON THE MODEL
enhancing the accuracy of anomaly detection. Our method integrates information from three different modalities—visual, audio, and text—by constructing more expressive multimodal representations that fully exploit the intrinsic semantics of the data, enabling the model to outperform methods relying solely on single-visual and other forms of bimodal methods across various metrics. In Table V, we provide a detailed comparison of the fine-grained performance on the XD-Violence dataset. Compared to coarse-grained analysis in Table III, fine-grained analysis can more accurately reflect the anomaly categories as well as the continuity and completeness of anomalous events, thus posing greater challenges and offering stronger representativeness. Specifically, compared to the state-of-theart methods AVVD [20] and VadCLIP [24], our method improves the average performance by 7.23% and 4.46%, respectively. This substantial improvement confirms both the efficacy and strength of our method while emphasizing that fine-grained analysis captures subtle details and the full scope of anomalous events. In complex VAD tasks, such analysis offers more precise feedback and broader opportunities for optimizing anomaly detection models.
D. Ablation Study#
- Analysis of the Contribution of Different Modalities to the Model: We conduct an in-depth exploration of the impact of different input modalities and their combinations on the model, as detailed in Table VI. The video, audio, and text modalities are represented as V , A, and T , respectively. The results show that multimodal combinations significantly outperform single-modal inputs in terms of performance, a finding that is also validated in Table IV. For instance, the joint of video and audio (video + audio, V + A) as well as the joint of text and video (text + video, T + V) improved performance by 1.08% and 4.10%, respectively, compared to using merely the video modality. The improvement can be attributed to the text modality, which provides more direct and structured information than the audio modality,
TABLE VII ANALYSIS OF THE CONTRIBUTION OF EACH COMPONENT TO THE MODEL
TABLE VIII COMPARISON BEFORE AND AFTER THE CONSTRUCTION OF ACPS
enhancing the model’s ability to understand and reason semantically. While audio contains some directional information, it is more susceptible to environmental noise, which affects its effectiveness. Furthermore, when all three modalities (video, audio, and text, V +A+T ) are combined, the model exhibits the best result. The underlying reason is that audio effectively enhances the model’s ability to better capture significant anomalous features in the video, while text further provides clear and accurate semantic direction, improving the model’s perception and discrimination capabilities.
- Analysis of the Contribution of Each Component to the Model: In Table VII, we conducted ablation experiments to evaluate the contributions of each component. The results reveal that multiple core components of the model have a positive impact. First, the temporal unit effectively models the temporal information of videos. Compared to raw visual representations, the temporal unit captures the relationships between frames, allowing the model to learn dynamic changes over time, as anomalies often involve gradual or abrupt changes over time. Second, the ACP integrates textual information while concurrently augmenting the model’s capacity to perceive visual anomalies. After the cross-modal fusion, the model can combine anomaly-related visual information with textual prompts, thereby improving the discrimination of anomalies. Additionally, the contrastive constraint effectively strengthens the model’s ability to differentiate between the two, particularly optimizing the performance on hard samples (i.e., ambiguous samples). Overall, as each component is progressively introduced, the model’s performance exhibits certain fluctuations. Although increasing the number of components leads to a moderate decline in execution efficiency, this reduction remains within a reasonable and controllable range, posing no substantial threat to the whole system’s real-time performance and stability. Ultimately, when all components work in unison, the model’s status reaches its optimum.
Fig. 5. Analysis of the number of learnable parameters.
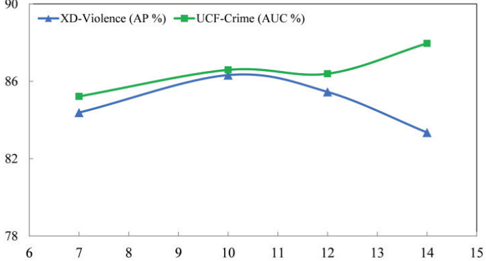
Fig. 6. Visualization of the differences before and after ACP construction.
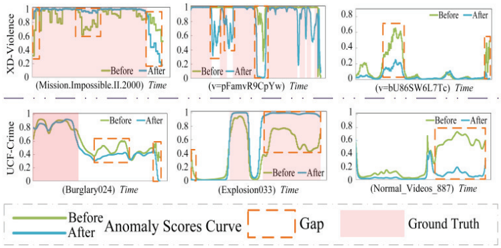
- Analysis of Learnable Parameter Count and ACPs: In the abnormal-aware module, we performed an in-depth analysis of the quantity of learnable parameters and systematically compared the changes before and after introducing anomaly knowledge. Specifically, as illustrated in Figs. 5 and 6, and Table VIII. In Fig. 5, considering the symmetry of learnable parameters, we chose to represent half the quantity to simplify the analysis of total parameters. We found that the sensitivity of performance to the number of learnable parameters varies across different datasets. It highlights the necessity of appropriately tuning the quantity of learnable parameters to improve network performance on particular datasets. Table VIII illustrates the variations before and after the implementation of anomaly knowledge. By integrating anomaly knowledge, all performance metrics of the model have been markedly improved. In the visualization difference map of Fig. 6, it is also clear that the boundaries of anomalous events are delineated more precisely, and the distinction between anomalous and normal states is enhanced. This phenomenon can be attributed to the introduction of anomaly knowledge, providing the model with richer representations and effectively enhancing the sensitivity and recognition ability for anomalous events.
- Effectiveness of Different Losses and the Selection of Loss Weights During Optimization: We conducted a systematic evaluation of the effectiveness of different loss functions and their weight selection in the overall optimization process, with the relevant results summarized in Tables IX and X. The results in Table IX indicate that a foundation of
TABLE IX VALIDATION OF THE EFFECTIVENESS OF DIFFERENT LOSS FUNCTIONS DURING THE OPTIMIZATION PROCESS
TABLE X EFFECT OF DIFFERENT λi ON THE OPTIMIZATION FUNCTION
TABLE XI IMPACT OF VISUAL SEGMENTS AND LEARNING RATE ON THE MODEL
coarse-grained optimization supplemented by fine-grained tuning can consistently enhance performance, and the introduction of contrastive loss further reinforces this improvement, thereby validating the complementarity between loss components at different levels. To verify the rationality of the weight configuration for each loss term in the objective function, we adopted the parameter settings of previous excellent methods and designed controlled variable experiments (detailed in Table X). The results show that, with the coarse-grained contrast weight fixed (i.e., λ1 = 0 . 15), appropriately adjusting the fine-grained weight gradually improves performance, reaching the highest effect under the optimal configuration; similarly, when the finegrained contrast weight is fixed, tuning the coarse-grained contrast weight also enhances performance. These findings demonstrate that the complementary interactions among the various loss terms in the multiloss joint optimization strategy positively contribute to the overall performance.
- Effective Partitioning of Visual Segments and Selection of Batch Size: Given that videos exhibit notable temporal continuity, segmenting the video for input is indispensable to capture its dynamic information. At the same time, properly configuring key hyperparameters—such as batch size—is critical for ensuring that the model achieves optimal convergence and efficient performance during training. In Table XI, we gradually increased the number of input visual segments from 64 to 512. The results indicate that as the amount of visual information per input increases, the model performance improves significantly. However, once the input information
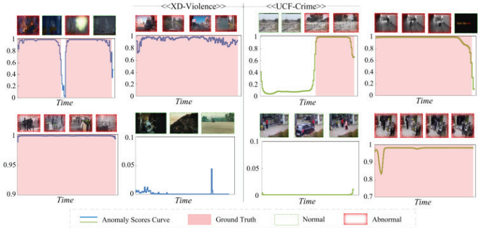
Fig. 7. Qualitative results analysis on XD-violence and UCF-crime.
TABLE XII IMPACT OF DIFFERENT BATCH SIZES ON PERFORMANCE
exceeds a certain threshold, the negative effects of information redundancy lead to a decline in performance. Furthermore, Table XII reveals that the optimal batch size varies considerably across different application scenarios. Therefore, batch size and related hyperparameters should be dynamically adjusted according to specific environments to achieve optimal performance.
E. Qualitative Comparison#
Fig. 7 presents the analysis of both abnormal and normal videos. For the anomalous videos, when abnormal events occur, the anomaly score curve experiences a substantial increase and maintains a high level for the duration of these events. This reflects the model’s ability to capture the occurrence of abnormal events in real time and effectively monitor their duration. The anomaly score curve steadily drops to lower values as the anomalous events come to an end, with minor oscillations within this range. Conversely, the anomaly score curve for normal videos remains consistently low, with occasional minor fluctuations that, while resembling abnormalities, do not reach the threshold required to trigger an anomaly warning. Here, it further validates its ability to maintain high sensitivity to abnormal events while effectively avoiding false positives for normal behaviors.
V. CONCLUSION#
In this article, we propose a multimodal dual-stream VAD network that can utilize video, audio, and textual information. In the coarse-grained stream, we first perform cross-modal fusion of temporally modeled visual and audio features, introduce contrastive learning to enhance the discriminative ability, enable preliminary identification of anomalies, and support subsequent fine-grained anomaly detection. The fine-grained stream integrates textual information by constructing ACPs, fully leveraging the semantic information carried by the text, and combining the cross-modal fusion features and corresponding anomaly scores from the coarse-grained stream. By employing a “coarse-support-fine” strategy, the model is able to effectively identify anomalies at different levels. Finally, we conducted systematic experiments, detailed visual analysis, and ablation studies on two large-scale datasets, the proposed method achieves optimal performance across multiple metrics. This can efficiently identify anomalous behaviors in industry monitoring, driving the development of intelligent surveillance systems, and supporting the realization of big data analysis and intelligent decision-making in the industry.
In future research, although we have explored relevant aspects about VLMs, there remains extensive and profound research potential in utilizing LLMs or VLMs for anomaly behavior or event reasoning and analysis. Therefore, future studies will focus on how to more effectively tap into and utilize the emergent capabilities to advance deep reasoning and precise descriptive analysis of abnormalities. Meanwhile, the emergent capabilities of general-purpose large models have already yielded preliminary success in VAD, and they still face significant limitations when analyzing highly specialized and complex anomalous vision. Thus, designing and training LLMs specifically for VAD in vertical domains will be an important direction.
REFERENCES#
[1] Y. Liu and H. Liang, “Review on the application of the nonlinear output frequency response functions to mechanical fault diagnosis,” IEEE Trans. Instrum. Meas., vol. 72, pp. 1–12, 2023.
[2] P. P. Liang, A. Zadeh, and L.-P. Morency, “Foundations & trends in multimodal machine learning: Principles, challenges, and open questions,” ACM Comput. Surveys, vol. 56, no. 10, pp. 1–42, Oct. 2024.
[3] F. Harrou, M. M. Hittawe, Y. Sun, and O. Beya, “Malicious attacks detection in crowded areas using deep learning-based approach,” IEEE Instrum. Meas. Mag., vol. 23, no. 5, pp. 57–62, Aug. 2020.
[4] T. Li and H. Yu, “Visual–inertial fusion-based human pose estimation: A review,” IEEE Trans. Instrum. Meas., vol. 72, pp. 1–16, 2023.
[5] L. Wang, X. Wang, F. Liu, M. Li, X. Hao, and N. Zhao, “Attentionguided MIL weakly supervised visual anomaly detection,” Measurement , vol. 209, Mar. 2023, Art. no. 112500.
[6] M. A. Abou-Khousa, M. S. U. Rahman, K. M. Donnell, and M. T. A. Qaseer, “Detection of surface cracks in metals using microwave and millimeter-wave nondestructive testing techniques—A review,” IEEE Trans. Instrum. Meas., vol. 72, pp. 1–18, 2023.
[7] H. Qi, X. Kong, Z. Shen, Z. Liu, and J. Gu, “Progressively learning dynamic level set for weakly supervised industrial defect segmentation,” IEEE Trans. Instrum. Meas., vol. 72, pp. 1–14, 2023.
[8] Y. Li, X. Wu, P. Li, and Y. Liu, “Ferrite beads surface defect detection based on spatial attention under weakly supervised learning,” IEEE Trans. Instrum. Meas., vol. 72, pp. 1–12, 2023.
[9] H. Du et al., “Uncovering what, why and how: A comprehensive benchmark for causation understanding of video anomaly,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2024, pp. 18793–18803.
[10] H. Park, J. Noh, and B. Ham, “Learning memory-guided normality for anomaly detection,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2020, pp. 14372–14381.
[11] M. Liu, Y. Jiao, J. Lu, and H. Chen, “Anomaly detection for medical images using teacher–student model with skip connections and multi-scale anomaly consistency,” IEEE Trans. Instrum. Meas., vol. 73, pp. 1–15, 2024.
[12] D. Wang, Q. Hu, and K. Wu, “Dual-branch network with memory for video anomaly detection,” Multimedia Syst., vol. 29, no. 1, pp. 247–259, Feb. 2023.
[13] R. Liu, W. Liu, H. Li, H. Wang, Q. Geng, and Y. Dai, “Metro anomaly detection based on light strip inductive key frame extraction and MAGAN network,” IEEE Trans. Instrum. Meas., vol. 71, pp. 1–14, 2022.
[14] J. Jiang, S. Wei, X. Xu, Y. Cui, and X. Liu, “Unsupervised anomaly detection and localization based on two-hierarchy normalizing flow,” IEEE Trans. Instrum. Meas., vol. 73, pp. 1–11, 2024.
[15] Y. Yan, D. Wang, G. Zhou, and Q. Chen, “Unsupervised anomaly segmentation via multilevel image reconstruction and adaptive attentionlevel transition,” IEEE Trans. Instrum. Meas., vol. 70, pp. 1–12, 2021.
[16] G. Yu, S. Wang, Z. Cai, X. Liu, E. Zhu, and J. Yin, “Video anomaly detection via visual cloze tests,” IEEE Trans. Inf. Forensics Security , vol. 18, pp. 4955–4969, 2023.
[17] C. Zhang, Y. Wang, and W. Tan, “MTHM: Self-supervised multi-task anomaly detection with hard example mining,” IEEE Trans. Instrum. Meas., vol. 72, pp. 1–13, 2023.
[18] Y. Tian, G. Pang, Y. Chen, R. Singh, J. W. Verjans, and G. Carneiro, “Weakly-supervised video anomaly detection with robust temporal feature magnitude learning,” in Proc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), Oct. 2021, pp. 4955–4966.
[19] V. Sevetlidis, G. Pavlidis, V. Balaska, A. Psomoulis, S. G. Mouroutsos, and A. Gasteratos, “Enhancing weakly supervised defect detection through anomaly-informed weighted training,” IEEE Trans. Instrum. Meas., vol. 73, pp. 1–10, 2024.
[20] P. Wu, X. Liu, and J. Liu, “Weakly supervised audio-visual violence detection,” IEEE Trans. Multimedia, vol. 25, pp. 1674–1685, 2023.
[21] P. Wu et al., “Not only look, but also listen: Learning multimodal violence detection under weak supervision,” in Proc. Eur. Conf. Comput. Vis., Jan. 2020, pp. 322–339.
[22] Y. Pu and X. Wu, “Audio-guided attention network for weakly supervised violence detection,” in Proc. 2nd Int. Conf. Consum. Electron. Comput. Eng. (ICCECE), Jan. 2022, pp. 219–223.
[23] H. Lv, Z. Yue, Q. Sun, B. Luo, Z. Cui, and H. Zhang, “Unbiased multiple instance learning for weakly supervised video anomaly detection,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2023, pp. 8022–8031.
[24] P. Wu et al., “VadCLIP: Adapting vision-language models for weakly supervised video anomaly detection,” in Proc. AAAI Conf. Artif. Intell. , vol. 38, Mar. 2024, pp. 6074–6082.
[25] Y. Pu, X. Wu, L. Yang, and S. Wang, “Learning prompt-enhanced context features for weakly-supervised video anomaly detection,” IEEE Trans. Image Process., vol. 33, pp. 4923–4936, 2024.
[26] P. Wu, J. Liu, X. He, Y. Peng, P. Wang, and Y. Zhang, “Toward video anomaly retrieval from video anomaly detection: New benchmarks and model,” IEEE Trans. Image Process., vol. 33, pp. 2213–2225, 2024.
[27] Z. Yang, J. Liu, and P. Wu, “Text prompt with normality guidance for weakly supervised video anomaly detection,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), vol. 32, Jun. 2024, pp. 18899–18908.
[28] P. Wu et al., “Open-vocabulary video anomaly detection,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2024, pp. 18297–18307.
[29] W. Sultani, C. Chen, and M. Shah, “Real-world anomaly detection in surveillance videos,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., Jun. 2018, pp. 6479–6488.
[30] X. Wu, T. Wang, Y. Li, P. Li, and Y. Liu, “A CAM-based weakly supervised method for surface defect inspection,” IEEE Trans. Instrum. Meas., vol. 71, pp. 1–10, 2022.
[31] C. Cao, Y. Lu, and Y. Zhang, “Context recovery and knowledge retrieval: A novel two-stream framework for video anomaly detection,” IEEE Trans. Image Process., vol. 33, pp. 1810–1825, 2024.
[32] S. Li, F. Liu, and L. Jiao, “Self-training multi-sequence learning with transformer for weakly supervised video anomaly detection,” in Proc. AAAI Conf. Artif. Intell., 2022, vol. 36, no. 2, pp. 1395–1403.
[33] D. Wei, Y. Liu, X. Zhu, J. Liu, and X. Zeng, “MSAF: Multimodal supervise-attention enhanced fusion for video anomaly detection,” IEEE Signal Process. Lett., vol. 29, pp. 2178–2182, 2022.
[34] C. Feng, Z. Chen, and A. Owens, “Self-supervised video forensics by audio-visual anomaly detection,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2023, pp. 10491–10503.
[35] L. Zanella, W. Menapace, M. Mancini, Y. Wang, and E. Ricci, “Harnessing large language models for training-free video anomaly detection,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2024, pp. 18527–18536.
[36] H. Zhang et al., “Holmes-VAD: Towards unbiased and explainable video anomaly detection via multi-modal LLM,” 2024, arXiv:2406.12235 .
[37] X. Hu et al., “Scaling up vision-language pretraining for image captioning,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2022, pp. 17959–17968.
[38] Z. Jiang, J. Araki, H. Ding, and G. Neubig, “How can we know when language models know? On the calibration of language models for question answering,” Trans. Assoc. Comput. Linguistics, vol. 9, pp. 962–977, Sep. 2021.
[39] K. Zhou, J. Yang, C. C. Loy, and Z. Liu, “Learning to prompt for visionlanguage models,” Int. J. Comput. Vis., vol. 130, no. 9, pp. 2337–2348, Sep. 2022.
[40] K. Zhou, J. Yang, C. C. Loy, and Z. Liu, “Conditional prompt learning for vision-language models,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., Jun. 2022, pp. 16795–16804.
[41] J. Kim, S. Yoon, T. Choi, and S. Sull, “Unsupervised video anomaly detection based on similarity with predefined text descriptions,” Sensors , vol. 23, no. 14, p. 6256, Jul. 2023.
[42] P. Jin, R. Takanobu, W. Zhang, X. Cao, and L. Yuan, “Chat-UniVi: Unified visual representation empowers large language models with image and video understanding,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2024, pp. 13700–13710.
[43] Q. Wang et al., “StableIdentity: Inserting anybody into anywhere at first sight,” 2024, arXiv:2401.15975 .
[44] J. Li, “Recent advances in end-to-end automatic speech recognition,” APSIPA Trans. Signal Inf. Process., vol. 11, no. 1, pp. 1–27, 2022.
[45] P. Pu Liang, A. Zadeh, and L.-P. Morency, “Foundations and trends in multimodal machine learning: Principles, challenges, and open questions,” 2022, arXiv:2209.03430 .
[46] J. Yu, J. Liu, Y. Cheng, R. Feng, and Y. Zhang, “Modality-aware contrastive instance learning with self-distillation for weakly-supervised audio-visual violence detection,” in Proc. 30th ACM Int. Conf. MultiMedia, Oct. 2022, pp. 6278–6287.
[47] Z. Zhang, B. Yang, and J. Ma, “Multiple constraints flow for weakly observable defect detection based on defect-free samples,” IEEE Trans. Instrum. Meas., vol. 73, pp. 1–13, 2024.
[48] Z. Liu et al., “Swin transformer: Hierarchical vision transformer using shifted windows,” in Proc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV) , Oct. 2021, pp. 9992–10002.
[49] A. Vaswani et al., “Attention is all you need,” in Proc. Adv. Neural Inf. Process. Syst. (NIPS), vol. 30, 2017, pp. 1–11.
[50] P. Lee, J. Wang, Y. Lu, and H. Byun, “Weakly-supervised temporal action localization by uncertainty modeling,” Proc. AAAI Conf. Artif. Intell., vol. 35, no. 3, pp. 1854–1862, May 2021.
[51] A. Paszke et al., “PyTorch: An imperative style, high-performance deep learning library,” in Proc. Adv. Neural Inf. Process. Syst. (NIPS), Jan. 2019, p. 32.
[52] H. Zhou, J. Yu, and W. Yang, “Dual memory units with uncertainty regulation for weakly supervised video anomaly detection,” in Proc. AAAI Conf. Artif. Intell., Jun. 2023, vol. 37, no. 3, pp. 3769–3777.
[53] J. Wang and A. Cherian, “GODS: Generalized one-class discriminative subspaces for anomaly detection,” in Proc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), Oct. 2019, pp. 8200–8210.
[54] P. Wu, J. Liu, M. Li, Y. Sun, and F. Shen, “Fast sparse coding networks for anomaly detection in videos,” Pattern Recognit., vol. 107, Nov. 2020, Art. no. 107515.
[55] M. Z. Zaheer, A. Mahmood, M. H. Khan, M. Segu, F. Yu, and S.I. Lee, “Generative cooperative learning for unsupervised video anomaly detection,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2022, pp. 14724–14734.
[56] A. Al-Lahham, M. Z. Zaheer, N. Tastan, and K. Nandakumar, “Collaborative learning of anomalies with privacy (CLAP) for unsupervised video anomaly detection: A new baseline,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2024, pp. 12416–12425.
[57] M. Zhang et al., “Multi-scale video anomaly detection by multi-grained spatio-temporal representation learning,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2024, pp. 17385–17394.
[58] H. Lv, C. Zhou, Z. Cui, C. Xu, Y. Li, and J. Yang, “Localizing anomalies from weakly-labeled videos,” IEEE Trans. Image Process., vol. 30, pp. 4505–4515, 2021.
[59] Y. Chen, Z. Liu, B. Zhang, W. Fok, X. Qi, and Y.-C. Wu, “MGFN: Magnitude-contrastive glance-and-focus network for weakly-supervised video anomaly detection,” in Proc. AAAI Conf. Artif. Intell., 2023, vol. 37, no. 1, pp. 387–395.
[60] H. K. Joo, K. Vo, K. Yamazaki, and N. Le, “CLIP-TSA: Clipassisted temporal self-attention for weakly-supervised video anomaly detection,” in Proc. IEEE Int. Conf. Image Process. (ICIP), Oct. 2023, pp. 3230–3234.
[61] Y. Su, Y. Tan, S. An, and M. Xing, “Anomalies cannot materialize or vanish out of thin air: A hierarchical multiple instance learning with position-scale awareness for video anomaly detection,” Exp. Syst. Appl. , vol. 254, Nov. 2024, Art. no. 124392.
[62] B. Scholkopf, R. C. Williamson, A. J. Smola, J. Shawe-Taylor, and ¨ ¨ J. C. Platt, “Support vector method for novelty detection,” in Proc. Adv. Neural Inf. Process. Syst., vol. 12, 1999, pp. 582–588.
[63] M. Hasan, J. Choi, J. Neumann, A. K. Roy-Chowdhury, and L. S. Davis, “Learning temporal regularity in video sequences,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2016, pp. 733–742.
[64] J.-C. Wu, H.-Y. Hsieh, D.-J. Chen, C.-S. Fuh, and T.-L. Liu, “Selfsupervised sparse representation for video anomaly detection,” in Proc. Eur. Conf. Comput. Vis. (ECCV), 2022, pp. 729–745.
[65] P. Wu and J. Liu, “Learning causal temporal relation and feature discrimination for anomaly detection,” IEEE Trans. Image Process. , vol. 30, pp. 3513–3527, 2021.
[66] T. Liu, C. Zhang, K.-M. Lam, and J. Kong, “Decouple and resolve: Transformer-based models for online anomaly detection from weakly labeled videos,” IEEE Trans. Inf. Forensics Security, vol. 18, pp. 15–28, 2023.
[67] C. Zhang et al., “Exploiting completeness and uncertainty of pseudo labels for weakly supervised video anomaly detection,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), Jun. 2023, pp. 16271–16280.
[68] S. Paul, S. Roy, and K. R.-C. Amit, “W-TALC: Weakly-supervised temporal activity localization and classification,” in Proc. Eur. Conf. Comput. Vis., Jan. 2018, pp. 563–579.
[69] S. Narayan, H. Cholakkal, F. S. Khan, and L. Shao, “3C-net: Category count and center loss for weakly-supervised action localization,” in Proc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), Oct. 2019, pp. 8678–8686.

Dicong Wang (Graduate Student Member, IEEE) is currently pursuing the joint Ph.D. degree with the College of Intelligence and Computing, Tianjin University, Tianjin, China, and the School of Electronic and Information Engineering, Lanzhou Jiaotong University, Lanzhou, China.
His research interests include computer vision and video anomaly detection.

Qilong Wang (Senior Member, IEEE) received the Ph.D. degree from the School of Information and Communication Engineering, Dalian University of Technology, Dalian, China, in 2018.
He is currently a Professor with Tianjin University, Tianjin, China. He has authored or co-authored more than 40 academic papers in top conferences and referred journals, including ICCV, CVPR, NeurIPS, ECCV, IEEE TRANSACTIONS ON PAT -TERN ANALYSIS AND MACHINE INTELLIGENCE , IEEE TRANSACTIONS ON IMAGE PROCESSING , and IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECH -NOLOGY. His research interests include visual understanding and deep learning, particularly deep models with high-order statistical modeling, and self-attention mechanism.
Prof. Wang served as the Area Chair for CVPR 2024 and 2025.

Qinghua Hu (Senior Member, IEEE) received the B.S., M.S., and Ph.D. degrees from Harbin Institute of Technology, Harbin, China, in 1999, 2002, and 2008, respectively.
He was a Post-Doctoral Fellow with the Department of Computing, The Hong Kong Polytechnic University, Hong Kong, from 2009 to 2011. He is currently the Chair Professor with the College of Intelligence and Computing, Tianjin University, Tianjin, China, and the Director of the SIG Granular Computing and Knowledge Discovery and Chinese
Association of Artificial Intelligence. He was supported by the Key Program and the National Natural Science Foundation of China. He has authored or coauthored over 300 peer-reviewed articles. His current research interests include uncertainty modeling in big data, machine learning with multimodality data, and intelligent unmanned systems.
Prof. Hu is an Associate Editor of IEEE TRANSACTIONS ON FUZZY SYSTEMS , Acta Automatica Sinica, and Acta Electronica Sinica .

Kaijun Wu (Member, IEEE) received the Ph.D. degree from Lanzhou Jiaotong University, Lanzhou, China, in 2017.
He is currently a Professor with the School of Electronics and Information Engineering, Lanzhou Jiaotong University. His research interests include intelligent algorithm optimization and image processing.