

SlowFastVAD: Video Anomaly Detection via Integrating Simple Detector and RAG-Enhanced Vision-Language Model#
Zongcan Ding ∗ Northwestern Polytechnical University Xi’an, China [email protected]
Guansong Pang#
Singapore Management University Singapore, Singapore [email protected]
Abstract#
Video anomaly detection (VAD) aims to identify unexpected events in videos and has wide applications in safety-critical domains. While semi-supervised methods trained on only normal samples have gained traction, they often su!er from high false alarm rates and poor interpretability. Recently, vision-language models (VLMs) have demonstrated strong multimodal reasoning capabilities, o!ering new opportunities for explainable anomaly detection. However, their high computational cost and lack of domain adaptation hinder real-time deployment and reliability. Inspired by dual complementary pathways in human visual perception, we propose SlowFastVAD, a hybrid framework that integrates a fast anomaly detector with a slow anomaly detector (namely a retrieval augmented generation (RAG) enhanced VLM), to address these limitations. Speci"cally, the fast detector “rst provides coarse anomaly con"dence scores, and only a small subset of ambiguous segments, rather than the entire video, is further analyzed by the slower yet more interpretable VLM for elaborate detection and reasoning. Furthermore, to adapt VLMs to domain-speci"c VAD scenarios, we construct a knowledge base including normal patterns based on few normal samples and abnormal patterns inferred by VLMs. During inference, relevant patterns are retrieved and used to augment prompts for anomaly reasoning. Finally, we smoothly fuse the anomaly con"dence of fast and slow detectors to enhance robustness of anomaly detection. Extensive experiments on four benchmarks demonstrate that SlowFastVAD e!ectively combines the strengths of both fast and slow detectors, and achieves remarkable detection accuracy and interpretability with signi"cantly reduced computational overhead, making it well-suited for real-world VAD applications with high reliability requirements. The code will be released upon acceptance.
∗ These authors contributed equally to this work.
† Corresponding author.
Haodong Zhang ∗ Northwestern Polytechnical University Xi’an, China [email protected]
Zhiwei Yang Xidian University Guangzhou, China [email protected]
Yanning Zhang Northwestern Polytechnical University Xi’an, China [email protected]
CCS Concepts#
- Computing methodologies → Scene anomaly detection; Activity recognition and understanding .
Keywords#
Video anomaly detection, Vision-language model, Semi-supervised learning, Interpretable learning
1 Introduction#
Video Anomaly Detection (VAD) aims to automatically identify abnormal events in video streams that deviate signi"cantly from typical normal patterns. It plays a vital role in a wide range of real-world applications [55 , 65 , 67]. Given the rarity and high acquisition cost of anomalous samples in real-world scenarios, increasing attention has been directed toward the semi-supervised VAD paradigm, which trains models exclusively on normal videos [30 , 34 , 75]. By learning the underlying distribution of normal patterns, these methods attempt to detect anomalies as deviations from expected behaviors during inference.
However, semi-supervised VAD methods su!er from several inherent limitations. Since these models are trained exclusively on normal samples, they are prone to misclassifying rare yet plausible normal behaviors as anomalies, leading to high false positive rates. Moreover, existing one-class detection approaches, such as those based on autoencoders [7 , 18 , 40 , 48 , 53 , 73 , 83], generative adversarial networks (GANs) [13 , 19 , 77], or di!usion models [10 , 15 , 70], often exhibit limited adaptability when deployed in complex and dynamic real-world environments. In addition, most of these methods rely on end-to-end deep neural networks that are trained to “t only the distribution of normal behaviors. As a result, their decisionmaking results are often monotonous and lack interpretability or reasoning, making them ill-suited for scenarios where transparency and explainability are crucial.
Peng Wu † Northwestern Polytechnical University Xi’an, China [email protected]
Peng Wang Northwestern Polytechnical University Xi’an, China [email protected]
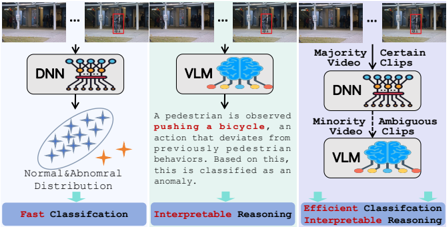
Majority ight). Certain . . b . b . ) . ) . . o . o . r Figure 1: Comparative analysis between conventional fast … … … detector based on DNN (Left), recent slow detectors based on Majori VLMs (Middle), and our SlowFastVAD (Right).
Video
DNN
Fast deo Classifcation data. For inst Interpretable ce, in the wid Reasoning elyused A g pedestrian gg id is observed ( pushing various a do bicycle mains a , a an d action that deviates d A from previously -supervise pedestrian d VAD ta behaviors ti . Based d on this t , i this grat is io classified n and sem as an an tic anomaly y unco . Normal&Abnomral eir multimodal Distribution Ms can e!ec Efficient edestrian Classifcation n street datas Interpretable tht “l Reasoning dt VLM ] t Minority ve demon Ambiguous trated gr Video demo Clips trated A dtiibd Recently, vision-language models (VLMs) have achieved remarkp pushing a bicycle, an ihdif Minority Ambiguous Video Clips able progress across various domains and have demonstrated great action that deviates from previously pedestrian VLM potential in the semi-supervised VAD task [71]. Bene"ting from behaviors. Based on this, this is classified as an Normal&Abnomral VLM their multimodal integration and semantic understanding abilities, anomaly. Distribution VLMs can e!ectively uncover latent behavioral patterns within Fast Classifcation Interpretable Reasoning Efficient Classifcation bli video data. For instance, in the widely-used pedestrian street dataset Interpretable Reasoning Ped2, VLMs can infer the normative pattern that “only pedestrians are allowed to walk on the sidewalk” by learning from normal videos. In complex real-world scenarios, such models are capable of learning and constructing semantic representations of normal patterns, thereby enabling more accurate identi"cation of anomalies that deviate from these learned norms. Furthermore, by leveraging their language generation capabilities and the established semantic rules, VLMs can provide clear reasoning for their detection results, signi"cantly enhancing the interpretability and trustworthiness.
Despite the promising potential of VLMs in the VAD task, their practical application still faces several critical challenges that warrant further investigation. First, VLMs are susceptible to the hallucination, where the generated reasoning or predictions deviate from the actual video content. For example, in Ped2, VLMs occasionally misinterpret normal pedestrian walking as a crowd gathering, thereby incorrectly labeling it as an anomalous event, resulting in semantically inconsistent judgments. Second, most current VLMs are pre-trained on general-purpose datasets, and their anomaly understanding is typically based on commonsense reasoning rather than task-speci"c behavioral modeling. Consequently, such models may misinterpret anomalies in speci"c environments due to semantic ambiguity. For instance, riding a bicycle on the sidewalk is treated as an anomalous event within the Ped2 dataset’s context. However, since such behavior is often deemed acceptable in real-world scenarios, the model may fail to detect it as an anomaly. Furthermore, from a deployment perspective, VLMs often incur substantial computational overhead and exhibit slow inference speeds. Performing dense inference on every video frame is particularly impractical in scenarios requiring real-time responses, such as public safety surveillance. These limitations signi"cantly hinder the practical utility of VLM-based VAD methods.
Inspired by the dual complementary pathways in human visual perception [12 , 74], namely, a cognition-driven pathway for precise understanding (slow) and an action-driven pathway for rapid
Clips
DNN
VLM
Fast V Classifcation VLM to gen DNN tar Interpretable te various v Reasoning isual de VLM st an A l pedestrian feedforw is ar observed d netwo pushing tiVL a M bicycle M bd , an action tion V that VLM deviates M based from slow previously bilitd pedestrian dtti behaviors ability a . Based nd de on te this ctio , this i is classified di as an t anomaly arios, w . Normal&Abnomral in speci"c s Distribution p Efficient Classifcation g f Interpretable criptions fro Reasoning m norm DNN aly d VLM orma Minority based fa Ambiguous t detecto Video ector Clips peci” Majority integrat Certain s the co Video g Clips l i . p . . . . . . . . Fast w Classifcation we propose a DNN bas l Interpretable ntropybase Reasoning d interve VLM equir A pedestrian d is observed pushing based a on bicycle the lan , n an ua action d that deviates from g h previously and incorp pedestrian orates the behaviors t . Based td on this , this ore is ta classified geted an as om an mal anomaly onal ov . Normal&Abnomral VLM towar Distribution high comp Efficient tion dete Classifcation ction strateg Interpretable d Reasoning g td bt DNN samp VLM p ti Minority descrip Ambiguous on of the Video escrip Clips on of Majority This proc ll b Certain ss of kn Video numb Clips r of n . i . i . a . s . . . a . ab . b … … … response (fast), and these pathways work in tandem to respond e !ectively even in extreme scenarios. This paper proposes a novel Majority Certain Video Clips VAD framework, SlowFastVAD, which integrates the complemenNN VLM p tary strengths of fast and slow detectors. The goal is to achieve e DNN #cient, accurate, and interpretable anomaly detection by combinA pedestrian is observed hibil Minority Ambiguous ing a traditional feedforward network based fast detector with a pushing a bicycle, an action that deviates from Video Clips high-generalization VLM based slow detector. Speci"cally, to enpreviously pedestrian behaviors. Based on this, VLM hance the adaptability and detection performance of large models this is classified as an anomaly. mal&Abnomral istribution in speci"c scenarios, we design a retrieval augmented generation Effiit Clifti (RAG) driven anomaly reasoning module. This module guides the t Classifcation Interpretable Reasoning Efficient Classifcation Interpretable Reasoning VLM to generate various visual descriptions from normal samples, summarizes normal patterns under the given context, and further leverages Chain-of-Thought (CoT) reasoning to infer po… … … tential abnormal patterns. These normal and abnormal patterns Majority Certain are structured into a knowledge base. This process of knowledge DNN VLM jy Video Clips base construction requires only a small number of normal samDNN VLM DNN ples, eliminating the requirement for full-sample training. During inference, the model retrieves relevant behavioral rules from the p pushing a bicycle, an ihdif Minority Ambiguous Video Clips knowledge base based on the language description of the current action that deviates from previously pedestrian VLM video segment and incorporates them into prompts to guide the behaviors. Based on this, this is classified as an rmal&Abnomral VLM VLM toward more targeted anomaly detection. To mitigate the anomaly. istribution high computational overhead associated with the VLM inference, t Classifcation Interpretable Reasoning Efficient Classifcation ttbli we propose an entropy-based intervention detection strategy. This Interpretable Reasoning strategy leverages the anomaly con"dence generated by the fast detector to identify video segments with high uncertainty, which are then selectively forwarded to the VLM-base slow detector for further analysis. This enables signi"cant improvements in detection accuracy and interpretability while maintaining computational e #ciency. Finally, we introduce a decision fusion mechanism that integrates the predictions from both fast and slow detectors, thereby enhancing the overall robustness of the framework. We illustrate the key di!erences between SlowFastVAD, traditional DNN-based fast detectors and VLM-based slow detector in Figure 1, and our SlowFastVAD e!ectively addresses the limitations of current fast detector, namely the limited generalization capability, poor interpretability, and high computational cost of slow detector.
- The main contributions of this work are summarized as follows: · We propose the SlowFastVAD framework, which, to our knowledge, is the “rst to innovatively integrate the traditional fast anomaly detector with slow yet interpretable VLM-based detector, achieving a synergy between e#ciency and explainability.
- We develop a RAG-driven anomaly reasoning module, in which VLM summarizes normal and abnormal patterns during training to construct a knowledge base. This knowledge base is then dynamically retrieved during inference to enhance prompts, improving the generalization to speci"c VAD scenarios.
- We design an entropy-based intervention detection strategy that e !ectively selects video segments likely to be misclassi"ed by the fast detector, precisely triggering the VLM inference. This strategy signi"cantly reduces overall computational costs.
- Extensive experiments on multiple public datasets demonstrate that our proposed SlowFastVAD e!ectively integrates the advantages of both fast and slow detectors, achieving state-of-the-art detection performance along with interpretable outputs.
2 Related Work#
2.1 Non-VLM-based Video Anomaly Detection#
2.1.1 Semi-supervised VAD. In semi-supervised VAD, training processing relies solely on normal samples, where the model learns normal patterns and identi"es deviations from these patterns during inference as anomalies. Under the current deep learning paradigm, semi-supervised VAD approaches can be broadly categorized based on the network architecture into three main types: autoencoderbased approaches, generative adversarial networks (GANs)-based approaches, and di!usion-based approaches. Autoencoder-based approaches utilize an encoder to compress input samples into lowdimensional latent representations and a decoder to reconstruct the original input from the latent space. Anomalies are detected by measuring the reconstruction error between the input and output [7 , 18 , 40 , 48 , 53 , 73 , 83]. GAN-based approaches consist of a generator and a discriminator. The generator learns to synthesize realistic normal samples, while the discriminator aims to distinguish between real and generated data. Test samples with low authenticity scores from the discriminator are classi"ed as anomalies [13 , 19 , 77]. Di!usion-based approaches progressively generate samples from noise through a reverse di!usion process. The quality of the generated samples is then used to assess the normality, with poor reconstruction indicating potential anomalies [10, 15, 70].
2.1.2 Weakly Supervised VAD. Weakly-supervised VAD utilizes both normal and abnormal samples during training, but lacks precise annotations of anomalies, and only coarse video-level labels are available. Current research mainly follows two paradigms: onestage multiple instance learning (MIL) approaches [29 , 54] and twostage self-training strategies [72 , 80]. To further improve detection performance, recent e!orts have explored various enhancement techniques, including temporal modeling, spatiotemporal modeling, MIL-based optimization, and feature metric learning. Speci"cally, temporal modeling captures sequential dependencies in videos, enabling the model to utilize contextual information [11 , 17 , 54 , 86]. Spatiotemporal modeling integrates spatial and temporal features to localize anomalous regions while suppressing background noise [26 , 54]. MIL-based optimization strategies address the limitation of conventional MIL methods that focus only on high-scoring segments, by incorporating external priors, such as textual knowledge, to improve anomaly localization [9 , 36]. Feature metric learning constructs a discriminative embedding space by clustering similar features and separating dissimilar ones, thereby enhancing the representation discrimination [14].
2.2 VLM-based Video Anomaly Detection#
2.2.1 Semi-supervised VAD. In the “eld of VAD, VLMs have demonstrated signi"cant potential and adaptability. Yang et al. proposed AnomalyRuler [71], which detects anomalies by integrating the inductive summarization and deductive reasoning capabilities of VLMs. Speci"cally, in the inductive phase, the model derives behavioral rules from a small number of normal samples, while in the deductive phase, it identi"es anomalous frames based on these rules. In addition, Jiang et al. introduced the VLAVAD framework [25], which employs cross-modal pre-trained models and leverages the reasoning capabilities of large language models (LLMs) to enhance the interpretability and e!ectiveness of VAD. However, due to the slow inference speed of VLMs, the overall processing time of these methods remains high. In contrast, our SlowFastVAD integrates conventional fast detectors with VLMs, enabling sparse yet deeper reasoning based on the initial outputs of the fast detector. This design e!ectively balances inference speed and detection accuracy.
2.2.2 Weakly Supervised VAD. VLMs have also been widely applied in weakly supervised VAD. They not only enhance anomaly detection performance through visual-language enhanced features (e.g., CLIP-TSA [21]) and cross-modal semantic alignment (e.g., VadCLIP [69], TPWNG [72], and STPrompts [68]), but also contribute to interpretability by generating descriptions for anomalous events, as demonstrated in the Holmes-VAU [82]. Moreover, VLMs can be leveraged for training-free anomaly detection by utilizing their extensive prior knowledge [35 , 79], o!ering advantages in rapid deployment and reduced computational cost. For instance, Zanella et al. [79] adopted an explainable approach in which re$ective questions are used to guide the model in generating anomaly scores, without requiring additional model training.
2.3 VLM-based Vision Tasks#
Currently, VLMs have made signi"cant progress and found widespread application in various vision “elds [57]. In image classi"cation, VLM enhances zero-shot classi"cation capabilities, especially in handling unknown object categories, showing excellent performance and supporting stronger domain generalization [1 , 22]. In semantic segmentation, VLM improves the ability to handle unseen categories signi"cantly by combining open-vocabulary techniques with image-text fusion [33 , 60]. In video generation, VLM is used to generate consistent and multi-scene video content, pushing forward the advancement of video generation technology [31]. In crossmodal retrieval, VLM improves the e!ectiveness and e#ciency by integrating image and language information [6 , 23]. In action recognition, VLM enhances the recognition of “ne-grained actions by combining pose information with language models, particularly excelling in action anticipation[39, 81].
3 Methodology#
3.1 Overview#
Our proposed method is illustrated in Figure 2, which consists of two branches: a fast DNN-based detector and a slow VLM-based detector. The fast detector is built upon an autoencoder-based architecture, o!ering high detection speed but limited interpretability. In contrast, the slow detector leverages VLMs, which provides strong interpretability at the cost of slower inference. By integrating multiple specialized components, our framework e!ectively combines the advantages of both detectors to achieve a balanced trade-o! between e#ciency and accuracy. The overall pipeline is as follows: The fast detector “rst performs preliminary detection and identi"es potentially ambiguous segments, which are then passed to the slow detector for further analysis. The slow detector generates both anomaly con"dence scores and interpretable descriptions. To select ambiguous segments more e!ectively, we propose an intervention detection strategy based on entropy measures. Additionally, to improve the adaptability of the VLM in speci"c anomaly detection
Figure 2: Overview of the proposed SlowFastVAD method. It consists of two branches: a fast DNN-based detector and a slow VLM-based detector. To seamlessly integrate the two detection branches and leverage their respective strengths, we designed three key components, i.e., intervention detection strategy, RAG-driven anomaly reasoning module, and integration mechanism, enabling an e!cient and interpretable VAD framework.
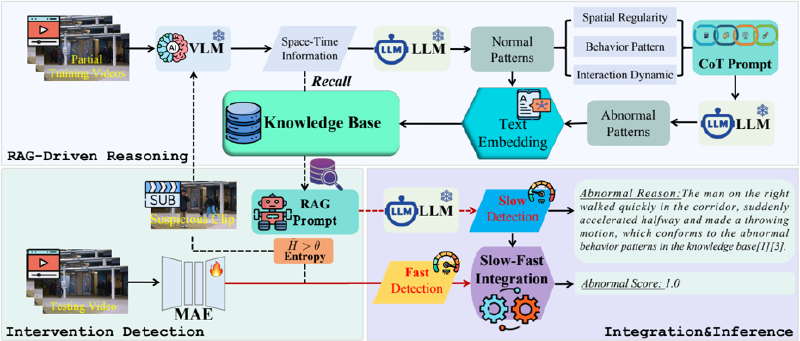
scenarios, we introduce an anomaly-oriented RAG module. This module constructs a knowledge base by extracting normal patterns from training videos and inferring potential abnormal patterns, thus enhancing scene-speci"c reasoning capabilities. Finally, an integration mechanism combines the outputs from both detectors to yield the “nal prediction. This mechanism mitigates hallucination e !ects commonly associated with VLMs and enables the system to achieve high detection accuracy, faster inference, and interpretable output.
3.2 Fast Detector#
3.2.1 Foundation Model. In the fast detector, we adopt the AEDMAE [48], which utilizes a lightweight masked autoencoder architecture. By incorporating motion gradient based weighting, selfdistillation training, and synthetic anomaly augmentation strategies, this method achieves fairly e#cient VAD. AED-MAE is characterized by its compact model size and extremely fast inference speed, reaching up to 1655 FPS (frame per second).
3.2.2 Intervention Detection Strategy. In the context of VAD, video frames that are easy to classify typically exhibit low variance in anomaly con"dence scores, resulting in low uncertainty, i.e., low entropy. However, since the fast detector is trained solely on normal samples via reconstruction, it may produce high reconstruction errors for normal-but-rare samples during inference, leading to noisy or $uctuating anomaly con"dence scores. Besides, in complex scenes where the test data deviates from distributions of the training set, the fast detector may fail to generalize e!ectively, again causing instability in anomaly con"dence scores. These $uctuations are re $ected as increased entropy in the anomaly con"dence scores.
To address this, we propose a novel entropy-based intervention detection strategy to identify and select ambiguous segments that are di#cult to accurately classify. Speci"cally, given a testing video, we take its frame-level anomaly con"dence scores from the fast detector as input and partition it into a set of non-overlapping subsequences = { } = 1 using a window size . For each subsequence , we compute its entropy. To account for temporal context, we apply a Gaussian “lter for smoothing, integrating the entropy values of neighboring subsequences to obtain a context-aware entropy score. Given that the anomaly con"dence scores are decimals ranging from 0 to 1, we adopt the di!erential entropy formula for calculation. The detailed calculation procedure is shown as follows.
We “rst estimate the probability density function of the obtained subsequence = { } =1 , where indicates the anomaly score of the -th video frame. Here, we employ the frequency distribution histogram to serve as an approximation of the probability density function for the subsequence . The following are the detailed steps: Firstly, determine the number of histogram bins as . Subsequently, calculate the di!erence between the maximum and minimum values within . Divide the obtained di!erence by the number of groups to derive the class interval, based on which the grouping intervals can be further ascertained. On this foundation, count the number of elements of within each grouping interval, and then compute the corresponding frequencies to obtain the frequency distribution histogram ↑ R . For each value in , “rst identify the group to which it belongs in the frequency distribution histogram , and take the frequency of that group as the probability of its occurrence. In this way, the “nal probability density function ˆ ˆ () of is obtained. Based on the obtained probability density function ˆ ˆ () of the subsequence , we
compute the di!erential entropy of as follows:
We further apply a Gaussian “lter (·) to , integrating the information from neighboring subsequences + , so as to obtain the “nal entropy value ˆ of , which is shown below:
We set a threshold to determine which subsequences are considered uncertain. If the entropy value of a certain subsequence exceeds , then the corresponding video segment = { } =1 will be fed into the slow detector for further analysis.
Moreover, to improve the interpretability of overall detection results, we also introduce a periodic sampling mechanism. Speci"cally, one video segment is sampled from every video segments and sent to the slow detector for semantic description and anomaly scoring. These results serve as global context cues that complement the “nal decision-making process with interpretable outputs.
3.3 Slow Detector#
3.3.1 Basic Procedure. The input to the slow detector is the ambiguous video segment identi"ed by the intervention detection strategy. In the VAD task, spatiotemporal information is of crucial importance [63 , 85]. Temporal information can capture the sequential evolution process of events and their durations, which helps to distinguish between normal and abnormal behaviors, because anomalies often manifest as sudden interruptions in the temporal dimension. Spatial information is divided into two parts: the foreground and the background. Foreground information focuses on the positions and motion patterns of foreground objects. Anomalies usually manifest as unusual spatial arrangements or sudden changes in positions. Background information focuses on the relatively stable scene characteristics. By understanding the background information, VLM and LLM can better extract and summarize the normal and abnormal patterns in the current scene. Based on this, is concatenated with the CoT prompt (refer to Appendix for details) and then fed into the VLM (denoted as ) to extract its spatiotemporal representation . Subsequently, the spatiotemporal representation is encoded into a vector by the embedding model text-embedding-v2 1 (denoted as ). Detailed processes can be presented as follows:
Based on the similarity between and constructed patterns, the top relevant patterns and their associated binary anomaly predictions (i.e., normal and abnormal) are retrieved from the constructed knowledge base D, which is introduced in the following section. Combine and to obtain the knowledge =
1 https://help.aliyun.com/zh/model-studio/user-guide/embedding
{(1 , 1) , ··· , ( , )} related to the current video. = ({( , , ( , )))|( , ) ↑ D}) (4)
where (·) denotes the similarity computation.
Finally, the extracted spatiotemporal representation and the retrieved knowledge are concatenated and combined with a CoT reasoning prompt to form a structured prompt = [; ]. This prompt is fed into LLM for step-by-step reasoning, producing anomaly scores along with corresponding interpretive descriptions .
3.3.2 RAG-driven Anomaly Reasoning. This module is designed to extract normal patterns from training videos, enabling VLM trained on general scenarios to better adapt to the speci"c VAD task. To achieve this, we apply a sparse temporal sampling strategy [59], where a segment containing consecutive frames is randomly selected from “xed-length segments of training videos. Throughout this process, we extensively incorporate the CoT prompt to guide the reasoning of models in a more interpretable and coherent manner. The overall procedure consists of four stages: visual description generation, pattern extraction and prediction, pattern re"nement and aggregation, and knowledge base construction.
Visual Description Generation: Here, we follow the same procedure described in Section 3.3.1 to extract the spatiotemporal representation for the video segment.
Pattern Extraction and Prediction: Based on the extracted spatiotemporal representations , we further employ the CoT prompt to guide the LLM in re"ning representative normal patterns N (e.g., “a person walking slowly on the road” or “a small group engaged in conversation”). Building upon these patterns, the model is further prompted to reason about spatial regularity, behavioral pattern, and interaction dynamic, thereby enabling the prediction of potential abnormal patterns A. This step not only encodes prior knowledge of normalcy but also enhances semantic interpretability of potential anomalies. The detailed processes are presented as follows:
where -denotes the reasoning of LLMs with the assist of CoT prompt.
Pattern Re"nement and Aggregation: After obtaining the initially extracted normal and abnormal patterns, we design a votingbased strategy for pattern re"nement and aggregation. Considering that normal patterns within the same video scene often exhibit high consistency, while abnormal patterns tend to be more diverse, we aggregate highly similar patterns to re"ne stable behavioral representations. Meanwhile, dissimilar patterns are retained to preserve behavioral diversity. This process results in a pattern set that is both representative and diverse, laying a solid foundation for subsequent knowledge base construction. Speci"cally, we process the patterns summarized from the videos within each scene separately. Here, we take the normal patterns as an example for illustration, and the abnormal patterns are processed in the same way. For the -th scene, the -th normal pattern is “rst compared for similarity with the existing patterns in the knowledge base. If the
average similarity between it and the existing patterns is below the threshold , it indicates that this pattern is dissimilar to the existing patterns in the knowledge base, and it will then be directly added to the knowledge base. Conversely, if the sum of similarities is not less than , we identify the “rst normal patterns in the knowledge base that are similar to it. These similar patterns are then aggregated and cleaned, and the aggregated and cleaned patterns are added to the knowledge base. Through continuous loop processing, after traversing all normal patterns of the -th scene, we “nally obtain the set N ↗ N of all processed normal patterns for the -th scene. After obtaining the set N ↗ N of normal patterns and the set A ↗ of abnormal patterns for the -th scene, we combine the two to obtain the set P of all patterns for this scene. The formula is expressed as follows:
Knowledge Base Construction: The cleaned normal and abnormal patterns P, along with their corresponding anomaly predictions , are structured into standardized data formats are then encoded into vector representations using the text-embedding-v2 1 model, thereby constructing the knowledge base tailored for the VAD task. Mathematically, the knowledge base D can be expressed as follows:
3.4 Slow-Fast Integration and Inference#
To derive the “nal anomaly con"dence score, we integrate from the fast detector and from the slow detector via a integration mechanism. First, we use the weighted-averaging method to obtain the initial fused , which is shown as follows:
where the weighting factor serves to balance the performance of fast and slow detectors. Subsequently, a Gaussian “lter is applied for smoothing. Moreover, the anomaly reasoning is generated by the slow detector, endowing the detection result with high interpretability.
4 Experiments#
4.1 Datasets and Evaluation Metrics#
4.1.1 Datasets. We evaluate the proposed method on four public datasets: UCSD Ped2 [38], Avenue [32], ShanghaiTech [42], and UBnormal [61]. UCSD Ped2 is a single-scene dataset captured on a pedestrian walkway that contains anomalies such as cyclists, skateboarders, and cars. Avenue is also a single-scene dataset, recorded on the main avenue of the CUHK campus, with anomalies including running and bicycling. ShanghaiTech is a more challenging multiscene dataset from 13 di!erent campus environments, characterized by variations in lighting conditions and camera perspectives. As the largest dataset for semi-supervised VAD, it comprises 270000 frames for training and approximately 50000 for testing. UBnormal is an open-set dataset comprising 29 synthetic scenes, where the sets of anomaly types in the training and testing splits are disjoint. For each dataset, we adopt the default training and testing splits under the semi-supervised setting, using only normal samples during training. The normal reference frames used by SlowFastVAD are randomly and uniformly sampled from normal training videos.
4.1.2 Evaluation Metrics. We follow recent related works [48 , 71] and report the frame-level Area Under the Curve (AUC) of the Receiver Operating Characteristic (ROC). Speci"cally, we compute both the Micro AUC and Macro AUC. For Micro AUC, all test frames from every video are merged into a single sequence, and AUC is calculated across the entire set. In contrast, Macro AUC is computed by “rst calculating the AUC for each individual test video, followed by averaging these scores to obtain the “nal result.
4.2 Implementation Details#
Our method is implemented using the PyTorch framework. Unless otherwise speci"ed, Qwen-VL-Max [3] is used as VLM for visual perception, while Qwen-Max [56] serves as LLM for spatiotemporal information aggregation and retrieval-augmented generation. For Qwen-VL-Max, the sampling temperature is set to 0.01, while for Qwen-Max, the sampling temperature is set to 1.1 during mode training and 0.7 during model testing. The default hyperparameter settings for SlowFastVAD are as follows: the window size of video segment is set to 8, and the random/uniform sampling interval is set to 20 during training and reduced to 10 during testing to ensure “ner temporal resolution for inference. in Eq (4) is set to 6, and the weighting factor in Eq (11) is empirically set to 0.8, 0.5, and 0.7 for Ped2, Avenue, and ShanghaiTech, respectively, to balance the fast and slow detectors. For the fast detector, we follow the con “guration used in AED-MAE [48].
4.3 Comparison with State-of-the-art Methods#
In this section, we compare the proposed SlowFastVAD with dozens of baseline VAD methods across four datasets to evaluate its detection performance. Notably, for a fair comparison, we restrict our evaluation to frame- or cube-centric methods, as object-centric methods completely remove background information and irrelevant content. As shown in Tables 1 and 2, SlowFastVAD achieves overall state-of-the-art results, particularly excelling on UCSD Ped2 and UBnormal datasets, with Micro AUC scores of 99.1% and 72.2%, respectively. These results demonstrate the strong generalization ability and detection accuracy across diverse scenarios. The key advantage of SlowFastVAD lies in its dual-branch (slow and fast) architecture, which fully leverages the ability of VLMs to re"ne and amend the initial predictions from the fast detector. This design achieves a balanced trade-o! between inference e#ciency and detection accuracy. Compared to traditional VAD approaches based on visual features and reconstruction costs, SlowFastVAD bene"ts from the semantic understanding and external prior knowledge provided by VLMs, enabling more robust anomaly detection. For instance, compared to previous best counterpart AED-MAE [48], our SlowFastVAD yields considerable gains across di!erent evaluation
Table 1: AUC scores of several state-of-the-art methods versus SlowFastVAD on Ped2 and Avenue datasets. The top three methods are shown in red, green, and blue.
| | | | Ped2 Avenue AUC (%) | Ped2 Avenue AUC (%) | Ped2 Avenue AUC (%) | Ped2 Avenue
| AUC (%) | ||||||
|---|---|---|---|---|---|---|
| Method | Reference | Year | AUC (%) | AUC (%) | AUC (%) | AUC (%) |
| Micro | Macro | Micro | Macro | |||
| LSHF [84] | PR | 2016 | 91.0 | - | - | - |
| AnomalyGAN [47] | ICIP | 2017 | 93.5 | - | - | - |
| FuturePred [27] | CVPR | 2018 | 95.4 | - | 85.1 | 81.7 |
| MC2ST [28] | BMVC | 2018 | 87.5 | - | 84.4 | - |
| DeepMIL [50] | CVPR | 2018 | - | - | - | - |
| PnP-CMA [46] | WACV | 2018 | 88.4 | - | - | - |
| MemAE [16] | ICCV | 2019 | 94.1 | - | 83.3 | - |
| NNC [20] | WACV | 2019 | - | - | 88.9 | - |
| BMAN [24] | TIP | 2019 | 96.6 | - | 90.0 | - |
| AMCVAD [41] | ICCV | 2019 | 96.2 | - | 86.9 | - |
| DeepOC [66] | TNNLS | 2019 | 96.9 | - | 86.6 | - |
| StreetScene [45] | WACV | 2020 | 88.3 | - | 72.0 | - |
| MNAD [44] | CVPR | 2020 | 97.0 | - | 82.8 | 86.8 |
| SCRD [51] | ACMMM | 2020 | - | - | 89.6 | - |
| CAC [62] | ACMMM | 2020 | - | - | 87.0 | - |
| VEC-AM [75] | ACMMM | 2020 | 97.3 | - | 90.2 | - |
| AEP [76] | TNNLS | 2021 | 97.3 | - | 90.2 | - |
| LNRA [2] | BMVC | 2021 | 96.5 | - | 87.1 | - |
| TimeSformer [5] | ICML | 2021 | - | - | - | - |
| SSPCAB [49]+[27] | CVPR | 2022 | - | - | 87.3 | 84.5 |
| SSPCAB [49]+[44] | CVPR | 2022 | - | - | 84.8 | 88.6 |
| GCL [78] | CVPR | 2022 | - | - | - | - |
| FastAno [43] | WACV | 2022 | 96.3 | - | 85.3 | - |
| S3R [64] | ECCV | 2022 | - | - | - | - |
| HSNBM [4] | ACMMM | 2022 | 95.2 | - | 91.6 | - |
| ERVAD [52] | ACMMM | 2022 | 97.1 | - | 92.7 | - |
| DM-UVAD [58] | ICIP | 2023 | - | - | - | - |
| FPDM [70] | ICCV | 2023 | - | - | 90.1 | - |
| SSMCTB [37]+[27] | TPAMI | 2023 | - | - | 89.1 | 84.8 |
| SSMCTB [37]+[44] | TPAMI | 2023 | - | - | 86.4 | 86.3 |
| AnomalyRuler [71] | ECCV | 2024 | 97.9 | - | 89.7 | - |
| AED-MAE [48] | CVPR | 2024 | 95.4 | 98.4 | 91.3 | 90.9 |
| SSAE [8] | TPAMI | 2024 | - | - | 90.2 | - |
| SlowFastVAD | — | — | 99.1 | 99.7 | 89.6 | 93.2 |
metrics. Furthermore, in contrast to VLM-only methods AnomalyRuler [71], SlowFastVAD not only achieves signi"cantly faster inference, but also delivers improved detection performance.
4.4 Ablation Studies#
4.4.1 Impact of Each Component. In this section, we conduct an ablation study on di!erent con"gurations of SlowFastVAD to evaluate the contribution of each component to overall VAD performance. The following con"gurations are considered: (1)Baseline: No additional components are used; the slow detector re-evaluates anomalies based solely on the fast detector’s results under uniform sampling; (2) + Intervention: Only the intervention strategy is added; (3) +Intervention+ Integration: Both the intervention and integration components are used; (4) Full Model: All components, including the RAG module, are applied. The performance comparison is presented in Table 3. We observe that the baseline setting with uniform sampling yields relatively conservative performance,
Table 2: AUC scores of several state-of-the-art methods versus SlowFastVAD on ShanghaiTech and UBnormal datasets. The top three methods are shown in red, green, and blue.
| | | | ShanghaiTech UBnormal () | ShanghaiTech UBnormal () | ShanghaiTech UBnormal () | ShanghaiTech UBnormal
| () | ||||||
|---|---|---|---|---|---|---|
| Method | Reference | Year | AUC (%) | AUC (%) | AUC (%) | AUC (%) |
| Method | Micro | Macro | Micro | Macro | ||
| FuturePred [27] | CVPR | 2018 | 72.8 | 80.6 | - | - |
| MC2ST [28] | BMVC | 2018 | - | - | - | - |
| DeepMIL [50] | CVPR | 2018 | - | 76.5 | 50.3 | 76.8 |
| MemAE [16] | ICCV | 2019 | 71.2 | - | - | - |
| MNAD [44] | CVPR | 2020 | 68.3 | 79.7 | - | - |
| SCRD [51] | ACMMM | 2020 | 74.7 | - | - | - |
| CAC [62] | ACMMM | 2020 | 79.3 | - | - | - |
| VEC-AM [75] | ACMMM | 2020 | 74.8 | - | - | - |
| LNRA [2] | BMVC | 2021 | 75.9 | - | - | - |
| TimeSformer [5] | ICML | 202 | - | - | 68.5 | 80.3 |
| SSPCAB [49]+[27] | CVPR | 2022 | 74.5 | 82.9 | - | - |
| SSPCAB [49]+[44] | CVPR | 2022 | 69.8 | 80.2 | - | - |
| GCL [78] | CVPR | 2022 | 78.9 | - | - | - |
| FastAno [43] | WACV | 2022 | 72.2 | - | - | - |
| S3R [64] | ECCV | 2022 | 80.4 | - | - | - |
| HSNBM [4] | ACMMM | 2022 | 76.5 | - | - | - |
| ERVAD [52] | ACMMM | 2022 | 79.3 | - | - | - |
| DM-UVAD [58] | ICIP | 2023 | 76.1 | - | - | - |
| FPDM [70] | ICCV | 2023 | 78.6 | - | 62.7 | - |
| SSMCTB [37]+[27] | TPAMI | 2023 | 74.6 | 83.3 | - | - |
| SSMCTB [37]+[44] | TPAMI | 2023 | 70.6 | 80.3 | - | - |
| AnomalyRuler [71] | ECCV | 2024 | 85.2 | - | 71.9 | - |
| AED-MAE [48] | CVPR | 2024 | 79.1 | 84.7 | 58.5 | 81.4 |
| SSAE [8] | TPAMI | 2024 | 80.5 | - | - | - |
| SlowFastVAD | — | — | 85.0 | 90.7 | 72.2 | 82.4 |
Table 3: Impact of each novel components on Ped2, Avenue, and ShanghaiTech datasets.
| Ped2 | Ped2 | Avenue | Avenue | ShanghaiTech | ShanghaiTech | |||
|---|---|---|---|---|---|---|---|---|
| Intervention Integration RAG | Intervention Integration RAG | Intervention Integration RAG | AUC | AUC | g | |||
| AUC (%) | g | |||||||
| AUC (%) | g | |||||||
| AUC (%) | g | |||||||
| AUC (%) | ||||||||
| Micro M | o Macro | o Micro | o Macro | Micro M | Macro | |||
| × | × | × | 87.8 | 89.6 | 80.1 | 86.1 | 76.3 | 82.3 |
| ⊋ | × | × | 90.6 | 91.1 | 85.8 | 89.0 | 80.6 | 83.6 |
| ⊋ | ⊋ | × | 94.3 | 97.2 | 86.1 | 88.5 | 83.9 | 88.4 |
| ⊋ | ⊋ | ⊋ | 99.1 | 99.7 | 89.6 | 93.2 | 85.0 | 90.7 |
indicating its limited ability to capture the key temporal segments of anomalous events. Introducing the intervention strategy leads to consistent improvements across all four datasets, especially on Avenue and ShanghaiTech, con"rming its e!ectiveness in guiding the model to focus on informative abnormal regions. Adding the integration mechanism further boosts performance, notably on Ped2 and ShanghaiTech, suggesting that it e!ectively combines the outputs of fast and slow detectors while better modeling temporal dependencies. Finally, incorporating the RAG module into the full model results in the best overall performance, with substantial gains on Ped2 and Avenue. This highlights the value of enhanced prompts generated by RAG in assisting the slow detector with more accurate anomaly reasoning. In summary, each component contributes to performance improvements to varying degrees. The “nal con “guration consistently outperforms others across all datasets, particularly excelling on Ped2 and ShanghaiTech.
Figure 3: Visualization of partial detection results on Ped2, Avenue, ShanghaiTech, and UBnormal. Three detection results are shown: the top displays anomaly scores generated solely by the fast detector; the middle shows the updated scores after intervention by the slow detector; the bottom presents the “nal results obtained through the integration of both detectors.
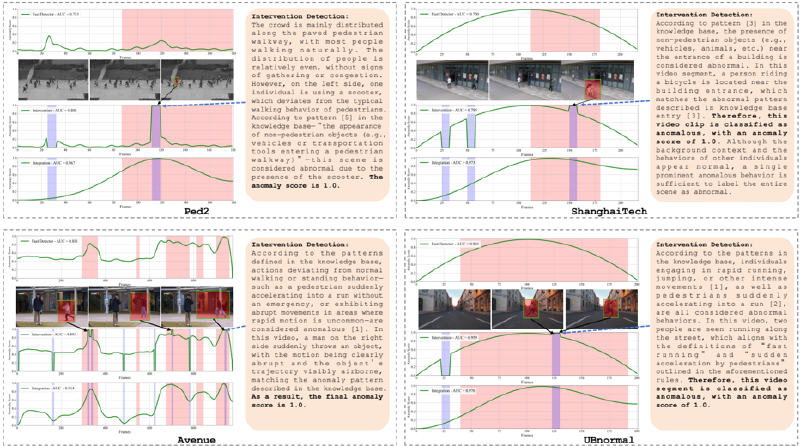
Table 4: Impact of fast detector, slow detector and the hybrid SlowFastVAD on Ped2, Avenue, and ShanghaiTech datasets.
| Ped2 | Ped2 | Avenue | Avenue | ShanghaiTech | ShanghaiTech | FPS | |
|---|---|---|---|---|---|---|---|
| Branch | AUC (%) | AUC (%) | AUC (%) | AUC (%) | AUC (%) | AUC (%) | FPS |
| Micro | Macro | Micro | Macro | Micro | Macro | ||
| Fast Detector | 95.4 | 98.4 | 91.3 | 90.9 | 79.1 | 84.7 | 1655 |
| Slow Detector | 98.4 | 99.0 | 74.5 | 78.0 | 87.7 | 85.6 | 0.5 |
| SlowFastVAD | 99.1 | 99.7 | 89.6 | 93.2 | 85.0 | 90.7 | 16 |
Note: The FPS results is obtained on a single RTX 3090 GPU. Due to limited GPU resources, the locally deployed model is Qwen2-VL-7B. If multiple GPUs are used for parallel processing, the speed can be further improved.
4.4.2 Impact of Di!erent Detectors. We further evaluated the performance of the fast detector, slow detector, and their hybrid approach across di!erent datasets, with the results summarized in Table 4. The fast detector alone demonstrates competitive performance and delivers high inference e#ciency (i.e., 1655 FPS) on all three datasets. In contrast, the slow detector exhibits relatively lower performance and considerably slow inference speed (i.e., 0.5 FPS), which can be attributed to the hallucination e!ects commonly observed in LLMs when operating independently, thereby compromising their ability to accurately identify anomalous events. By integrating both detectors, the hybrid approach achieves the superior overall performance across all datasets. Although a slight decrease in Micro AUC is observed on Avenue dataset, the dual-branch combination e!ectively suppresses hallucination e!ects, signi"cantly reducing false positives and false negatives while leveraging the strengths of the fast detector. Moreover, the hybrid approach maintains a favorable balance between detection accuracy and real-time inference (16 FPS), making it a practical and robust solution for VAD in diverse scenarios. Moreover, this also substantiates the e!ectiveness of our biologically inspired design, which emulates the human visual system’s dual complementary pathways, namely, mimicking the coordination between rapid action-oriented responses and slower cognition-driven reasoning.
4.5 Qualitative Analyses#
Figure 3 visualizes the detection results of our SlowFastVAD and its variants on di!erent datasets. The abnormal parts are highlighted with green bounding boxes in video frames. In the detection result, the red sections represent video segments labeled as abnormal in ground truth, while the blue sections represent the detection results after the intervention of slow detector. It is evident that using only the fast detector can achieve relatively good detection performance; However, it still su!ers from noticeable false positives and false negatives, especially as observed in samples from Ped2 and Avenue. By incorporating the slow detector based on VLM through the intervention stragety to analyze suspicious regions, the local detection performance is signi"cantly improved. Nevertheless, the localized enhancements have limited in$uence on the overall prediction. Therefore, the “nal integration of the fast and slow
detectors via a Gaussian “lter leads to a more globally consistent improvement, further enhancing overall detection performance.
In addition, we present several representative reasoning results from the slow detector. Due to space limitations, we randomly select a subset of intervention segments for illustration. Compared to the fast detector, which relies on simple data “tting to produce anomaly scores, the VLM-based slow detector leverages both pretrained knowledge and domain-speci"c information introduced via the RAG module to enable brain-inspired deep reasoning over events, thereby producing more interpretable and accurate anomaly assessments.
5 Conclusion#
In this work, we introduce SlowFastVAD, a novel hybrid framework that integrates a fast anomaly detector with a retrieval augmented generation enhanced vision-language model to achieve both e#ciency and interpretability in video anomaly detection. The fast detector provides initial detection results, while several ambiguous segments are selectively analyzed by the slower yet more explainable VLM, reducing unnecessary computational overhead. By leveraging this dual-branch detection pipeline, our method e!ectively balances computational cost and detection accuracy. Speci"cally, the proposed entropy-based intervention strategy ensures that only uncertain segments are processed by the VLM, while the construction of a domain-adapted knowledge base further enhances the VLM’s adaptability to speci"c VAD scenarios. Extensive experiments conducted on four datasets demonstrate that SlowFastVAD outperforms existing methods, achieving state-of-the-art detection performance while maintaining interpretability. In the future, we will further explore task-speci"c foundation models centered on VAD and continue to enhance reasoning e#ciency.
References#
[1] Sravanti Addepalli, Ashish Ramayee Asokan, Lakshay Sharma, and R Venkatesh Babu. 2024. Leveraging vision-language models for improving domain generalization in image classi"cation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 23922–23932.
[2] Marcella Astrid, Muhammad Zaigham Zaheer, Jae-Yeong Lee, and Seung-Ik Lee. 2021. Learning not to reconstruct anomalies. arXiv preprint arXiv:2110.09742 (2021).
[3] Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. 2023. Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond. arXiv preprint arXiv:2308.12966 (2023).
[4] Qianyue Bao, Fang Liu, Yang Liu, Licheng Jiao, Xu Liu, and Lingling Li. 2022. Hierarchical scene normality-binding modeling for anomaly detection in surveillance videos. In Proceedings of the 30th ACM international conference on multimedia . 6103–6112.
[5] Gedas Bertasius, Heng Wang, and Lorenzo Torresani. 2021. Is space-time attention all you need for video understanding?. In ICML, Vol. 2. 4.
[6] Davide Ca!agni, Federico Cocchi, Nicholas Moratelli, Sara Sarto, Marcella Cornia, Lorenzo Baraldi, and Rita Cucchiara. 2024. Wiki-llava: Hierarchical retrievalaugmented generation for multimodal llms. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 1818–1826.
[7] Ruichu Cai, Hao Zhang, Wen Liu, Shenghua Gao, and Zhifeng Hao. 2021. Appearance-motion memory consistency network for video anomaly detection. In Proceedings of the AAAI conference on arti!cial intelligence, Vol. 35. 938–946.
[8] Congqi Cao, Hanwen Zhang, Yue Lu, Peng Wang, and Yanning Zhang. 2024. Scene-dependent prediction in latent space for video anomaly detection and anticipation. IEEE Transactions on Pattern Analysis and Machine Intelligence (2024).
[9] Junxi Chen, Liang Li, Li Su, Zheng-Jun Zha, and Qingming Huang. 2024. Promptenhanced multiple instance learning for weakly supervised video anomaly detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 18319–18329.
[10] Kai Cheng, Yaning Pan, Yang Liu, Xinhua Zeng, and Rui Feng. 2024. Denoising di!usion-augmented hybrid video anomaly detection via reconstructing noised frames. In Proceedings of the Thirty-Third International Joint Conference on Arti!cial Intelligence. 695–703.
[11] MyeongAh Cho, Minjung Kim, Sangwon Hwang, Chaewon Park, Kyungjae Lee, and Sangyoun Lee. 2023. Look around for anomalies: Weakly-supervised anomaly detection via context-motion relational learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 12137–12146.
[12] Christoph Feichtenhofer, Haoqi Fan, Jitendra Malik, and Kaiming He. 2019. Slowfast networks for video recognition. In Proceedings of the IEEE/CVF international conference on computer vision. 6202–6211.
[13] Xinyang Feng, Dongjin Song, Yuncong Chen, Zhengzhang Chen, Jingchao Ni, and Haifeng Chen. 2021. Convolutional transformer based dual discriminator generative adversarial networks for video anomaly detection. In Proceedings of the 29th ACM International Conference on Multimedia. 5546–5554.
[14] Joseph Fioresi, Ishan Rajendrakumar Dave, and Mubarak Shah. 2023. Ted-spad: Temporal distinctiveness for self-supervised privacy-preservation for video anomaly detection. In Proceedings of the IEEE/CVF international conference on computer vision. 13598–13609.
[15] Alessandro Flaborea, Luca Collorone, Guido Maria D’Amely Di Melendugno, Stefano D’Arrigo, Bardh Prenkaj, and Fabio Galasso. 2023. Multimodal motion conditioned di!usion model for skeleton-based video anomaly detection. In Proceedings of the IEEE/CVF international conference on computer vision. 10318– 10329.
[16] Dong Gong, Lingqiao Liu, Vuong Le, Budhaditya Saha, Moussa Reda Mansour, Svetha Venkatesh, and Anton van den Hengel. 2019. Memorizing normality to detect anomaly: Memory-augmented deep autoencoder for unsupervised anomaly detection. In Proceedings of the IEEE/CVF international conference on computer vision. 1705–1714.
[17] Chao Huang, Chengliang Liu, Jie Wen, Lian Wu, Yong Xu, Qiuping Jiang, and Yaowei Wang. 2022. Weakly supervised video anomaly detection via self-guided temporal discriminative transformer. IEEE Transactions on Cybernetics 54, 5 (2022), 3197–3210.
[18] Chao Huang, Jie Wen, Chengliang Liu, and Yabo Liu. 2024. Long short-term dynamic prototype alignment learning for video anomaly detection. In Proceedings of the Thirty-Third International Joint Conference on Arti!cial Intelligence . 866–874.
[19] Chao Huang, Jie Wen, Yong Xu, Qiuping Jiang, Jian Yang, Yaowei Wang, and David Zhang. 2022. Self-supervised attentive generative adversarial networks for video anomaly detection. IEEE transactions on neural networks and learning systems 34, 11 (2022), 9389–9403.
[20] Radu Tudor Ionescu, Sorina Smeureanu, Marius Popescu, and Bogdan Alexe. 2019. Detecting abnormal events in video using narrowed normality clusters. In 2019 IEEE winter conference on applications of computer vision (WACV). IEEE, 1951–1960.
[21] Hyekang Kevin Joo, Khoa Vo, Kashu Yamazaki, and Ngan Le. 2023. Clip-tsa: Clipassisted temporal self-attention for weakly-supervised video anomaly detection. In 2023 IEEE International Conference on Image Processing (ICIP). IEEE, 3230–3234.
[22] Yannis Kalantidis, Giorgos Tolias, et al . 2024. Label propagation for zero-shot classi"cation with vision-language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 23209–23218.
[23] Jing Yu Koh, Ruslan Salakhutdinov, and Daniel Fried. 2023. Grounding language models to images for multimodal inputs and outputs. In International Conference on Machine Learning. PMLR, 17283–17300.
[24] Sangmin Lee, Hak Gu Kim, and Yong Man Ro. 2019. BMAN: Bidirectional multiscale aggregation networks for abnormal event detection. IEEE Transactions on Image Processing 29 (2019), 2395–2408.
[25] Changkang Li and Yalong Jiang. 2024. VLAVAD: Vision-Language Models Assisted Unsupervised Video Anomaly Detection. (2024).
[26] Guoqiu Li, Guanxiong Cai, Xingyu Zeng, and Rui Zhao. 2022. Scale-aware spatiotemporal relation learning for video anomaly detection. In European Conference on Computer Vision. Springer, 333–350.
[27] Wen Liu, Weixin Luo, Dongze Lian, and Shenghua Gao. 2018. Future frame prediction for anomaly detection–a new baseline. In Proceedings of the IEEE conference on computer vision and pattern recognition. 6536–6545.
[28] Yusha Liu, Chun-Liang Li, and Barnabás Póczos. 2018. Classi"er two sample test for video anomaly detections.. In BMVC. 71.
[29] Yang Liu, Jing Liu, Mengyang Zhao, Shuang Li, and Liang Song. 2022. Collaborative Normality Learning Framework for Weakly Supervised Video Anomaly Detection. IEEE Transactions on Circuits and Systems II: Express Briefs 69, 5 (2022), 2508–2512. doi:10.1109/TCSII.2022.3161061
[30] Yang Liu, Zhaoyang Xia, Mengyang Zhao, Donglai Wei, Yuzheng Wang, Siao Liu, Bobo Ju, Gaoyun Fang, Jing Liu, and Liang Song. 2023. Learning causalityinspired representation consistency for video anomaly detection. In Proceedings of the 31st ACM international conference on multimedia. 203–212.
[31] Fuchen Long, Zhaofan Qiu, Ting Yao, and Tao Mei. 2024. VideoStudio: Generating Consistent-Content and Multi-Scene Videos. In European Conference on Computer Vision. Springer, 468–485.
[32] Cewu Lu, Jianping Shi, and Jiaya Jia. 2013. Abnormal Event Detection at 150 FPS in MATLAB. In 2013 IEEE International Conference on Computer Vision. 2720–2727. doi:10.1109/ICCV.2013.338
[33] Jiayun Luo, Siddhesh Khandelwal, Leonid Sigal, and Boyang Li. 2024. Emergent open-vocabulary semantic segmentation from o!-the-shelf vision-language models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 4029–4040.
[34] Weixin Luo, Wen Liu, Dongze Lian, and Shenghua Gao. 2021. Future frame prediction network for video anomaly detection. IEEE transactions on pattern analysis and machine intelligence 44, 11 (2021), 7505–7520.
[35] Hui Lv and Qianru Sun. 2024. Video anomaly detection and explanation via large language models. arXiv preprint arXiv:2401.05702 (2024).
[36] Hui Lv, Zhongqi Yue, Qianru Sun, Bin Luo, Zhen Cui, and Hanwang Zhang. 2023. Unbiased multiple instance learning for weakly supervised video anomaly detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 8022–8031.
[37] Neelu Madan, Nicolae-C%t%lin Ristea, Radu Tudor Ionescu, Kamal Nasrollahi, Fahad Shahbaz Khan, Thomas B Moeslund, and Mubarak Shah. 2023. Selfsupervised masked convolutional transformer block for anomaly detection. IEEE Transactions on Pattern Analysis and Machine Intelligence 46, 1 (2023), 525–542.
[38] Vijay Mahadevan, Weixin Li, Viral Bhalodia, and Nuno Vasconcelos. 2010. Anomaly detection in crowded scenes. In 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. 1975–1981. doi:10.1109/CVPR.2010.5539872
[39] Himangi Mittal, Nakul Agarwal, Shao-Yuan Lo, and Kwonjoon Lee. 2024. Can’t make an Omelette without Breaking some Eggs: Plausible Action Anticipation using Large Video-Language Models. In 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 18580–18590.
[40] Romero Morais, Vuong Le, Truyen Tran, Budhaditya Saha, Moussa Mansour, and Svetha Venkatesh. 2019. Learning Regularity in Skeleton Trajectories for Anomaly Detection in Videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) .
[41] Trong-Nguyen Nguyen and Jean Meunier. 2019. Anomaly detection in video sequence with appearance-motion correspondence. In Proceedings of the IEEE/CVF international conference on computer vision. 1273–1283.
[42] Carl Olsson, Marcus Carlsson, Fredrik Andersson, and Viktor Larsson. 2017. Nonconvex Rank/Sparsity Regularization and Local Minima. In 2017 IEEE International Conference on Computer Vision (ICCV). 332–340. doi:10.1109/ICCV.2017.44
[43] Chaewon Park, MyeongAh Cho, Minhyeok Lee, and Sangyoun Lee. 2022. FastAno: Fast anomaly detection via spatio-temporal patch transformation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. 2249–2259.
[44] Hyunjong Park, Jongyoun Noh, and Bumsub Ham. 2020. Learning memoryguided normality for anomaly detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 14372–14381.
[45] Bharathkumar Ramachandra and Michael Jones. 2020. Street scene: A new dataset and evaluation protocol for video anomaly detection. In Proceedings of the IEEE/CVF winter conference on applications of computer vision. 2569–2578.
[46] Mahdyar Ravanbakhsh, Moin Nabi, Hossein Mousavi, Enver Sangineto, and Nicu Sebe. 2018. Plug-and-play cnn for crowd motion analysis: An application in abnormal event detection. In 2018 IEEE Winter Conference on Applications of Computer Vision (WACV). IEEE, 1689–1698.
[47] Mahdyar Ravanbakhsh, Moin Nabi, Enver Sangineto, Lucio Marcenaro, Carlo Regazzoni, and Nicu Sebe. 2017. Abnormal event detection in videos using generative adversarial nets. In 2017 IEEE international conference on image processing (ICIP). IEEE, 1577–1581.
[48] Nicolae-C Ristea, Florinel-Alin Croitoru, Radu Tudor Ionescu, Marius Popescu, Fahad Shahbaz Khan, and Mubarak Shah. 2024. Self-Distilled Masked AutoEncoders are E#cient Video Anomaly Detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 15984–15995.
[49] Nicolae-C%t%lin Ristea, Neelu Madan, Radu Tudor Ionescu, Kamal Nasrollahi, Fahad Shahbaz Khan, Thomas B Moeslund, and Mubarak Shah. 2022. Selfsupervised predictive convolutional attentive block for anomaly detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition . 13576–13586.
[50] Waqas Sultani, Chen Chen, and Mubarak Shah. 2018. Real-world anomaly detection in surveillance videos. In Proceedings of the IEEE conference on computer vision and pattern recognition. 6479–6488.
[51] Che Sun, Yunde Jia, Yao Hu, and Yuwei Wu. 2020. Scene-aware context reasoning for unsupervised abnormal event detection in videos. In Proceedings of the 28th ACM international conference on multimedia. 184–192.
[52] Che Sun, Yunde Jia, and Yuwei Wu. 2022. Evidential reasoning for video anomaly detection. In Proceedings of the 30th ACM International Conference on Multimedia . 2106–2114.
[53] Shengyang Sun and Xiaojin Gong. 2023. Hierarchical semantic contrast for scene-aware video anomaly detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 22846–22856.
[54] Shengyang Sun and Xiaojin Gong. 2023. Long-short temporal co-teaching for weakly supervised video anomaly detection. In 2023 IEEE International Conference on Multimedia and Expo (ICME). IEEE, 2711–2716.
[55] Shengyang Sun, Jiashen Hua, Junyi Feng, Dongxu Wei, Baisheng Lai, and Xiaojin Gong. 2024. TDSD: Text-driven scene-decoupled weakly supervised video anomaly detection. In Proceedings of the 32nd ACM International Conference on Multimedia. 5055–5064.
[56] Qwen Team. 2024. Qwen2.5 technical report. arXiv preprint arXiv:2412.15115 (2024).
[57] Xiaoyu Tian, Junru Gu, Bailin Li, Yicheng Liu, Yang Wang, Zhiyong Zhao, Kun Zhan, Peng Jia, Xianpeng Lang, and Hang Zhao. 2024. Drivevlm: The convergence of autonomous driving and large vision-language models. arXiv preprint arXiv:2402.12289 (2024).
[58] Anil Osman Tur, Nicola Dall’Asen, Cigdem Beyan, and Elisa Ricci. 2023. Exploring di!usion models for unsupervised video anomaly detection. In 2023 IEEE international conference on image processing (ICIP). IEEE, 2540–2544.
[59] Limin Wang, Yuanjun Xiong, Zhe Wang, Yu Qiao, Dahua Lin, Xiaoou Tang, and Luc Van Gool. 2016. Temporal segment networks: Towards good practices for deep action recognition. In European conference on computer vision. Springer, 20–36.
[60] Yuan Wang, Rui Sun, Naisong Luo, Yuwen Pan, and Tianzhu Zhang. 2024. Image-to-image matching via foundation models: A new perspective for openvocabulary semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 3952–3963.
[61] Zejin Wang, Jiazheng Liu, Guoqing Li, and Hua Han. 2022. Blind2Unblind: Self-Supervised Image Denoising with Visible Blind Spots. In 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2017–2026. doi:10. 1109/CVPR52688.2022.00207
[62] Ziming Wang, Yuexian Zou, and Zeming Zhang. 2020. Cluster attention contrast for video anomaly detection. In Proceedings of the 28th ACM international conference on multimedia. 2463–2471.
[63] Jie Wu, Wei Zhang, Guanbin Li, Wenhao Wu, Xiao Tan, Yingying Li, Errui Ding, and Liang Lin. 2021. Weakly-supervised spatio-temporal anomaly detection in surveillance video. arXiv preprint arXiv:2108.03825 (2021).
[64] Jhih-Ciang Wu, He-Yen Hsieh, Ding-Jie Chen, Chiou-Shann Fuh, and Tyng-Luh Liu. 2022. Self-supervised sparse representation for video anomaly detection. In European Conference on Computer Vision. Springer, 729–745.
[65] Peng Wu, Jing Liu, Xiangteng He, Yuxin Peng, Peng Wang, and Yanning Zhang. 2024. Toward video anomaly retrieval from video anomaly detection: New benchmarks and model. IEEE Transactions on Image Processing 33 (2024), 2213– 2225.
[66] Peng Wu, Jing Liu, and Fang Shen. 2019. A deep one-class neural network for anomalous event detection in complex scenes. IEEE transactions on neural networks and learning systems 31, 7 (2019), 2609–2622.
[67] Peng Wu, Chengyu Pan, Yuting Yan, Guansong Pang, Peng Wang, and Yanning Zhang. 2024. Deep Learning for Video Anomaly Detection: A Review. arXiv preprint arXiv:2409.05383 (2024).
[68] Peng Wu, Xuerong Zhou, Guansong Pang, Zhiwei Yang, Qingsen Yan, Peng Wang, and Yanning Zhang. 2024. Weakly supervised video anomaly detection and localization with spatio-temporal prompts. In Proceedings of the 32nd ACM International Conference on Multimedia. 9301–9310.
[69] Peng Wu, Xuerong Zhou, Guansong Pang, Lingru Zhou, Qingsen Yan, Peng Wang, and Yanning Zhang. 2024. Vadclip: Adapting vision-language models for weakly supervised video anomaly detection. In Proceedings of the AAAI Conference on Arti!cial Intelligence, Vol. 38. 6074–6082.
[70] Cheng Yan, Shiyu Zhang, Yang Liu, Guansong Pang, and Wenjun Wang. 2023. Feature prediction di!usion model for video anomaly detection. In Proceedings of the IEEE/CVF international conference on computer vision. 5527–5537.
[71] Yuchen Yang, Kwonjoon Lee, Behzad Dariush, Yinzhi Cao, and Shao-Yuan Lo. 2024. Follow the rules: reasoning for video anomaly detection with large language models. In European Conference on Computer Vision. Springer, 304–322.
[72] Zhiwei Yang, Jing Liu, and Peng Wu. 2024. Text prompt with normality guidance for weakly supervised video anomaly detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 18899–18908.
[73] Zhiwei Yang, Jing Liu, Zhaoyang Wu, Peng Wu, and Xiaotao Liu. 2023. Video Event Restoration Based on Keyframes for Video Anomaly Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 14592–14601.
[74] Zheyu Yang, Taoyi Wang, Yihan Lin, Yuguo Chen, Hui Zeng, Jing Pei, Jiazheng Wang, Xue Liu, Yichun Zhou, Jianqiang Zhang, et al . 2024. A vision chip with complementary pathways for open-world sensing. Nature 629, 8014 (2024), 1027–1033.
[75] Guang Yu, Siqi Wang, Zhiping Cai, En Zhu, Chuanfu Xu, Jianping Yin, and Marius Kloft. 2020. Cloze test helps: E!ective video anomaly detection via learning to complete video events. In Proceedings of the 28th ACM international conference on multimedia. 583–591.
[76] Jongmin Yu, Younkwan Lee, Kin Choong Yow, Moongu Jeon, and Witold Pedrycz. 2021. Abnormal event detection and localization via adversarial event prediction. IEEE transactions on neural networks and learning systems 33, 8 (2021), 3572–3586.
[77] Muhammad Zaigham Zaheer, Jin-Ha Lee, Marcella Astrid, and Seung-Ik Lee. 2020. Old Is Gold: Rede"ning the Adversarially Learned One-Class Classi"er
Training Paradigm. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) .
- [78] M Zaigham Zaheer, Arif Mahmood, M Haris Khan, Mattia Segu, Fisher Yu, and Seung-Ik Lee. 2022. Generative cooperative learning for unsupervised video anomaly detection. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 14744–14754.
- [79] Luca Zanella, Willi Menapace, Massimiliano Mancini, Yiming Wang, and Elisa Ricci. 2024. Harnessing large language models for training-free video anomaly detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 18527–18536.
- [80] Chen Zhang, Guorong Li, Yuankai Qi, Shuhui Wang, Laiyun Qing, Qingming Huang, and Ming-Hsuan Yang. 2023. Exploiting Completeness and Uncertainty of Pseudo Labels for Weakly Supervised Video Anomaly Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) . 16271–16280.
- [81] Haosong Zhang, Mei Chee Leong, Liyuan Li, and Weisi Lin. 2024. PeVL: PoseEnhanced Vision-Language Model for Fine-Grained Human Action Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 18857–18867.
- [82] Huaxin Zhang, Xiaohao Xu, Xiang Wang, Jialong Zuo, Xiaonan Huang, Changxin Gao, Shanjun Zhang, Li Yu, and Nong Sang. 2024. Holmes-vau: Towards long-term video anomaly understanding at any granularity. arXiv preprint arXiv:2412.06171 (2024).
- [83] Menghao Zhang, Jingyu Wang, Qi Qi, Pengfei Ren, Haifeng Sun, Zirui Zhuang, Huazheng Wang, Lei Zhang, and Jianxin Liao. 2024. Video Anomaly Detection via Progressive Learning of Multiple Proxy Tasks. In Proceedings of the 32nd ACM International Conference on Multimedia. 4719–4728.
- [84] Ying Zhang, Huchuan Lu, Lihe Zhang, Xiang Ruan, and Shun Sakai. 2016. Video anomaly detection based on locality sensitive hashing “lters. Pattern Recognition 59 (2016), 302–311.
- [85] Yiru Zhao, Bing Deng, Chen Shen, Yao Liu, Hongtao Lu, and Xian-Sheng Hua. 2017. Spatio-temporal autoencoder for video anomaly detection. In Proceedings of the 25th ACM international conference on Multimedia. 1933–1941.
- [86] Hang Zhou, Junqing Yu, and Wei Yang. 2023. Dual memory units with uncertainty regulation for weakly supervised video anomaly detection. In Proceedings of the AAAI Conference on Arti!cial Intelligence, Vol. 37. 3769–3777.